华为精英202010OD[第一题]
题意:给一个数n,寻找两个质数相乘等于n,按从小到大输出这两个数。
例子
输入
1 | 15 |
输出:
1 | 3 5 |
输入:
1 | 27 |
输出:
1 | -1 -1 |
题解
1 | package main |
问题:大数据会占用非常多的时间,导致超时。
华为精英202010OD[第二题]
题意: 返回特定水仙花个数,如果没有对应的水仙花数。返回最后一个水仙花乘上个数m。
例子:
输入:第一行是位数,第二行是第n个水仙花数。
1 | 3 |
100 - 999153为第一个水仙花数。
输出:
1 | 153 |
解法
1 | package main |
华为精英202010OD[第三题]
模拟内存申请和释放。
输入:
1 | 2 |
输出:
1 | 0 |
解法
1 | package main |
409. 最长回文串[简单]
给定一个包含大写字母和小写字母的字符串,找到通过这些字母构造成的最长的回文串。
在构造过程中,请注意区分大小写。比如 “Aa” 不能当做一个回文字符串。
注意:
假设字符串的长度不会超过 1010。
示例 1:
输入:
“abccccdd”
输出:
7
解释:
我们可以构造的最长的回文串是”dccaccd”, 它的长度是 7。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/longest-palindrome
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路
存储字母出现的次数,偶数直接加起来,奇数去掉一位之后再加起来。
1 | func longestPalindrome(s string) int { |
剑指 Offer 50. 第一个只出现一次的字符[简单]
在字符串 s 中找出第一个只出现一次的字符。如果没有,返回一个单空格。 s 只包含小写字母。
示例:
s = “abaccdeff”
返回 “b”
s = “”
返回 “ “
限制:
0 <= s 的长度 <= 50000
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/di-yi-ge-zhi-chu-xian-yi-ci-de-zi-fu-lcof
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func firstUniqChar(s string) byte { |
463. 岛屿的周长[简单]
给定一个包含 0 和 1 的二维网格地图,其中 1 表示陆地 0 表示水域。
网格中的格子水平和垂直方向相连(对角线方向不相连)。整个网格被水完全包围,但其中恰好有一个岛屿(或者说,一个或多个表示陆地的格子相连组成的岛屿)。
岛屿中没有“湖”(“湖” 指水域在岛屿内部且不和岛屿周围的水相连)。格子是边长为 1 的正方形。网格为长方形,且宽度和高度均不超过 100 。计算这个岛屿的周长。
示例 :
输入:
[[0,1,0,0],
[1,1,1,0],
[0,1,0,0],
[1,1,0,0]]
输出: 16
解释: 它的周长是下面图片中的 16 个黄色的边:
通过次数49,973提交次数70,121
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/island-perimeter
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func islandPerimeter(grid [][]int) int { |
500. 键盘行[简单]
给定一个单词列表,只返回可以使用在键盘同一行的字母打印出来的单词。键盘如下图所示。
示例:
输入: [“Hello”, “Alaska”, “Dad”, “Peace”]
输出: [“Alaska”, “Dad”]
注意:
你可以重复使用键盘上同一字符。
你可以假设输入的字符串将只包含字母。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/keyboard-row
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func findWords(words []string) []string { |
5539. 按照频率将数组升序排序[简单]
给你一个整数数组 nums ,请你将数组按照每个值的频率 升序 排序。如果有多个值的频率相同,请你按照数值本身将它们 降序 排序。
请你返回排序后的数组。
示例 1:
输入:nums = [1,1,2,2,2,3]
输出:[3,1,1,2,2,2]
解释:’3’ 频率为 1,’1’ 频率为 2,’2’ 频率为 3 。
示例 2:
输入:nums = [2,3,1,3,2]
输出:[1,3,3,2,2]
解释:’2’ 和 ‘3’ 频率都为 2 ,所以它们之间按照数值本身降序排序。
示例 3:
输入:nums = [-1,1,-6,4,5,-6,1,4,1]
输出:[5,-1,4,4,-6,-6,1,1,1]
提示:
1 <= nums.length <= 100
-100 <= nums[i] <= 100
解法
1 | func frequencySort(nums []int) []int { |
575. 分糖果[简单]
给定一个偶数长度的数组,其中不同的数字代表着不同种类的糖果,每一个数字代表一个糖果。你需要把这些糖果平均分给一个弟弟和一个妹妹。返回妹妹可以获得的最大糖果的种类数。
示例 1:
输入: candies = [1,1,2,2,3,3]
输出: 3
解析: 一共有三种种类的糖果,每一种都有两个。
最优分配方案:妹妹获得[1,2,3],弟弟也获得[1,2,3]。这样使妹妹获得糖果的种类数最多。
示例 2 :
输入: candies = [1,1,2,3]
输出: 2
解析: 妹妹获得糖果[2,3],弟弟获得糖果[1,1],妹妹有两种不同的糖果,弟弟只有一种。这样使得妹妹可以获得的糖果种类数最多。
注意:
数组的长度为[2, 10,000],并且确定为偶数。
数组中数字的大小在范围[-100,000, 100,000]内。
通过次数28,693提交次数42,364
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/distribute-candies
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func min(x,y int) int { |
594. 最长和谐子序列[简单]
和谐数组是指一个数组里元素的最大值和最小值之间的差别正好是1。
现在,给定一个整数数组,你需要在所有可能的子序列中找到最长的和谐子序列的长度。
示例 1:
输入: [1,3,2,2,5,2,3,7]
输出: 5
原因: 最长的和谐数组是:[3,2,2,2,3].
说明: 输入的数组长度最大不超过20,000.
通过次数17,044提交次数34,875
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/longest-harmonious-subsequence
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
计算各个数字的个数,寻找相邻为1和的最大值。
1 | func findLHS(nums []int) int { |
599. 两个列表的最小索引总和[简单]
假设Andy和Doris想在晚餐时选择一家餐厅,并且他们都有一个表示最喜爱餐厅的列表,每个餐厅的名字用字符串表示。
你需要帮助他们用最少的索引和找出他们共同喜爱的餐厅。 如果答案不止一个,则输出所有答案并且不考虑顺序。 你可以假设总是存在一个答案。
示例 1:
输入:
[“Shogun”, “Tapioca Express”, “Burger King”, “KFC”]
[“Piatti”, “The Grill at Torrey Pines”, “Hungry Hunter Steakhouse”, “Shogun”]
输出: [“Shogun”]
解释: 他们唯一共同喜爱的餐厅是“Shogun”。
示例 2:
输入:
[“Shogun”, “Tapioca Express”, “Burger King”, “KFC”]
[“KFC”, “Shogun”, “Burger King”]
输出: [“Shogun”]
解释: 他们共同喜爱且具有最小索引和的餐厅是“Shogun”,它有最小的索引和1(0+1)。
提示:
两个列表的长度范围都在 [1, 1000]内。
两个列表中的字符串的长度将在[1,30]的范围内。
下标从0开始,到列表的长度减1。
两个列表都没有重复的元素。
通过次数18,694提交次数36,230
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/minimum-index-sum-of-two-lists
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
先找最小索引,再找最小索引对应的元素
1 | func findRestaurant(list1 []string, list2 []string) []string { |
645. 错误的集合[简单]
集合 S 包含从1到 n 的整数。不幸的是,因为数据错误,导致集合里面某一个元素复制了成了集合里面的另外一个元素的值,导致集合丢失了一个整数并且有一个元素重复。
给定一个数组 nums 代表了集合 S 发生错误后的结果。你的任务是首先寻找到重复出现的整数,再找到丢失的整数,将它们以数组的形式返回。
示例 1:
输入: nums = [1,2,2,4]
输出: [2,3]
注意:
给定数组的长度范围是 [2, 10000]。
给定的数组是无序的。
通过次数24,480提交次数58,029
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/set-mismatch
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func findErrorNums(nums []int) []int { |
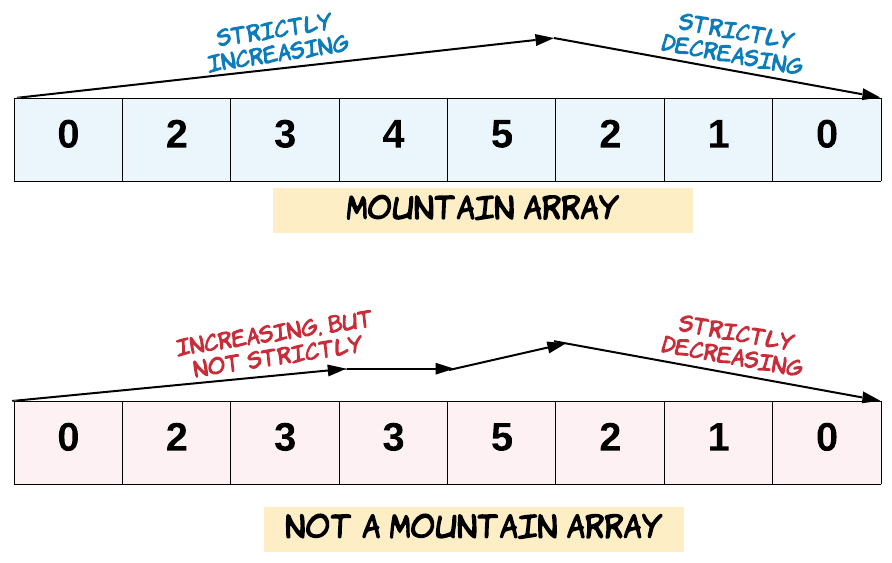
941. 有效的山脉数组[简单]
给定一个整数数组 A,如果它是有效的山脉数组就返回 true,否则返回 false。
让我们回顾一下,如果 A 满足下述条件,那么它是一个山脉数组:
A.length >= 3
在 0 < i < A.length - 1 条件下,存在 i 使得:
A[0] < A[1] < … A[i-1] < A[i]
A[i] > A[i+1] > … > A[A.length - 1]
示例 1:
输入:[2,1]
输出:false
示例 2:
输入:[3,5,5]
输出:false
示例 3:
输入:[0,3,2,1]
输出:true
提示:
0 <= A.length <= 10000
0 <= A[i] <= 10000
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/valid-mountain-array
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func validMountainArray(A []int) bool { |
690. 员工的重要性[简单]
给定一个保存员工信息的数据结构,它包含了员工唯一的id,重要度 和 直系下属的id。
比如,员工1是员工2的领导,员工2是员工3的领导。他们相应的重要度为15, 10, 5。那么员工1的数据结构是[1, 15, [2]],员工2的数据结构是[2, 10, [3]],员工3的数据结构是[3, 5, []]。注意虽然员工3也是员工1的一个下属,但是由于并不是直系下属,因此没有体现在员工1的数据结构中。
现在输入一个公司的所有员工信息,以及单个员工id,返回这个员工和他所有下属的重要度之和。
示例 1:
输入: [[1, 5, [2, 3]], [2, 3, []], [3, 3, []]], 1
输出: 11
解释:
员工1自身的重要度是5,他有两个直系下属2和3,而且2和3的重要度均为3。因此员工1的总重要度是 5 + 3 + 3 = 11。
注意:
一个员工最多有一个直系领导,但是可以有多个直系下属
员工数量不超过2000。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/employee-importance
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func getImportance(employees []*Employee, id int) int { |
720. 词典中最长的单词[简单]
给出一个字符串数组words组成的一本英语词典。从中找出最长的一个单词,该单词是由words词典中其他单词逐步添加一个字母组成。若其中有多个可行的答案,则返回答案中字典序最小的单词。
若无答案,则返回空字符串。
示例 1:
输入:
words = [“w”,”wo”,”wor”,”worl”, “world”]
输出:”world”
解释:
单词”world”可由”w”, “wo”, “wor”, 和 “worl”添加一个字母组成。
示例 2:
输入:
words = [“a”, “banana”, “app”, “appl”, “ap”, “apply”, “apple”]
输出:”apple”
解释:
“apply”和”apple”都能由词典中的单词组成。但是”apple”的字典序小于”apply”。
提示:
所有输入的字符串都只包含小写字母。
words数组长度范围为[1,1000]。
words[i]的长度范围为[1,30]。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/longest-word-in-dictionary
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func longestWord(words []string) string { |
748. 最短补全词[简单]
给定一个字符串牌照 licensePlate 和一个字符串数组 words ,请你找出并返回 words 中的 最短补全词 。
如果单词列表(words)中的一个单词包含牌照(licensePlate)中所有的字母,那么我们称之为 补全词 。在所有完整词中,最短的单词我们称之为 最短补全词 。
单词在匹配牌照中的字母时要:
忽略牌照中的数字和空格。
不区分大小写,比如牌照中的 “P” 依然可以匹配单词中的 “p” 字母。
如果某个字母在牌照中出现不止一次,那么该字母在补全词中的出现次数应当一致或者更多。
例如:licensePlate = “aBc 12c”,那么它由字母 ‘a’、’b’ (忽略大写)和两个 ‘c’ 。可能的 补全词 是 “abccdef”、”caaacab” 以及 “cbca” 。
题目数据保证一定存在一个最短补全词。当有多个单词都符合最短补全词的匹配条件时取单词列表中最靠前的一个。
示例 1:
输入:licensePlate = “1s3 PSt”, words = [“step”, “steps”, “stripe”, “stepple”]
输出:”steps”
说明:最短补全词应该包括 “s”、”p”、”s” 以及 “t”。在匹配过程中我们忽略牌照中的大小写。
“step” 包含 “t”、”p”,但只包含一个 “s”,所以它不符合条件。
“steps” 包含 “t”、”p” 和两个 “s”。
“stripe” 缺一个 “s”。
“stepple” 缺一个 “s”。
因此,”steps” 是唯一一个包含所有字母的单词,也是本样例的答案。
示例 2:
输入:licensePlate = “1s3 456”, words = [“looks”, “pest”, “stew”, “show”]
输出:”pest”
说明:存在 3 个包含字母 “s” 且有着最短长度的补全词,”pest”、”stew”、和 “show” 三者长度相同,但我们返回最先出现的补全词 “pest” 。
示例 3:
输入:licensePlate = “Ah71752”, words = [“suggest”,”letter”,”of”,”husband”,”easy”,”education”,”drug”,”prevent”,”writer”,”old”]
输出:”husband”
示例 4:
输入:licensePlate = “OgEu755”, words = [“enough”,”these”,”play”,”wide”,”wonder”,”box”,”arrive”,”money”,”tax”,”thus”]
输出:”enough”
示例 5:
输入:licensePlate = “iMSlpe4”, words = [“claim”,”consumer”,”student”,”camera”,”public”,”never”,”wonder”,”simple”,”thought”,”use”]
输出:”simple”
提示:
1 <= licensePlate.length <= 7
licensePlate 由数字、大小写字母或空格 ‘ ‘ 组成
1 <= words.length <= 1000
1 <= words[i].length <= 15
words[i] 由小写英文字母组成
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/shortest-completing-word
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func shortestCompletingWord(licensePlate string, words []string) string { |
705. 设计哈希集合[简单]
不使用任何内建的哈希表库设计一个哈希集合
具体地说,你的设计应该包含以下的功能
add(value):向哈希集合中插入一个值。
contains(value) :返回哈希集合中是否存在这个值。
remove(value):将给定值从哈希集合中删除。如果哈希集合中没有这个值,什么也不做。
示例:
MyHashSet hashSet = new MyHashSet();
hashSet.add(1);
hashSet.add(2);
hashSet.contains(1); // 返回 true
hashSet.contains(3); // 返回 false (未找到)
hashSet.add(2);
hashSet.contains(2); // 返回 true
hashSet.remove(2);
hashSet.contains(2); // 返回 false (已经被删除)
注意:
所有的值都在 [0, 1000000]的范围内。
操作的总数目在[1, 10000]范围内。
不要使用内建的哈希集合库。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/design-hashset
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | type MyHashSet struct { |
706. 设计哈希映射[简单]
不使用任何内建的哈希表库设计一个哈希映射
具体地说,你的设计应该包含以下的功能
put(key, value):向哈希映射中插入(键,值)的数值对。如果键对应的值已经存在,更新这个值。
get(key):返回给定的键所对应的值,如果映射中不包含这个键,返回-1。
remove(key):如果映射中存在这个键,删除这个数值对。
示例:
MyHashMap hashMap = new MyHashMap();
hashMap.put(1, 1);
hashMap.put(2, 2);
hashMap.get(1); // 返回 1
hashMap.get(3); // 返回 -1 (未找到)
hashMap.put(2, 1); // 更新已有的值
hashMap.get(2); // 返回 1
hashMap.remove(2); // 删除键为2的数据
hashMap.get(2); // 返回 -1 (未找到)
注意:
所有的值都在 [0, 1000000]的范围内。
操作的总数目在[1, 10000]范围内。
不要使用内建的哈希库。
通过次数18,111提交次数31,074
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/design-hashmap
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | type MyHashMap struct { |
811. 子域名访问计数[简单]
一个网站域名,如”discuss.leetcode.com”,包含了多个子域名。作为顶级域名,常用的有”com”,下一级则有”leetcode.com”,最低的一级为”discuss.leetcode.com”。当我们访问域名”discuss.leetcode.com”时,也同时访问了其父域名”leetcode.com”以及顶级域名 “com”。
给定一个带访问次数和域名的组合,要求分别计算每个域名被访问的次数。其格式为访问次数+空格+地址,例如:”9001 discuss.leetcode.com”。
接下来会给出一组访问次数和域名组合的列表cpdomains 。要求解析出所有域名的访问次数,输出格式和输入格式相同,不限定先后顺序。
示例 1:
输入:
[“9001 discuss.leetcode.com”]
输出:
[“9001 discuss.leetcode.com”, “9001 leetcode.com”, “9001 com”]
说明:
例子中仅包含一个网站域名:”discuss.leetcode.com”。按照前文假设,子域名”leetcode.com”和”com”都会被访问,所以它们都被访问了9001次。
示例 2
输入:
[“900 google.mail.com”, “50 yahoo.com”, “1 intel.mail.com”, “5 wiki.org”]
输出:
[“901 mail.com”,”50 yahoo.com”,”900 google.mail.com”,”5 wiki.org”,”5 org”,”1 intel.mail.com”,”951 com”]
说明:
按照假设,会访问”google.mail.com” 900次,”yahoo.com” 50次,”intel.mail.com” 1次,”wiki.org” 5次。
而对于父域名,会访问”mail.com” 900+1 = 901次,”com” 900 + 50 + 1 = 951次,和 “org” 5 次。
注意事项:
cpdomains 的长度小于 100。
每个域名的长度小于100。
每个域名地址包含一个或两个”.”符号。
输入中任意一个域名的访问次数都小于10000。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/subdomain-visit-count
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func subdomainVisits(cpdomains []string) []string { |
5561. 获取生成数组中的最大值[简单]
给你一个整数 n 。按下述规则生成一个长度为 n + 1 的数组 nums :
nums[0] = 0
nums[1] = 1
当 2 <= 2 * i <= n 时,nums[2 * i] = nums[i]
当 2 <= 2 * i + 1 <= n 时,nums[2 * i + 1] = nums[i] + nums[i + 1]
返回生成数组 nums 中的 最大 值。
示例 1:
输入:n = 7
输出:3
解释:根据规则:
nums[0] = 0
nums[1] = 1
nums[(1 * 2) = 2] = nums[1] = 1
nums[(1 * 2) + 1 = 3] = nums[1] + nums[2] = 1 + 1 = 2
nums[(2 * 2) = 4] = nums[2] = 1
nums[(2 * 2) + 1 = 5] = nums[2] + nums[3] = 1 + 2 = 3
nums[(3 * 2) = 6] = nums[3] = 2
nums[(3 * 2) + 1 = 7] = nums[3] + nums[4] = 2 + 1 = 3
因此,nums = [0,1,1,2,1,3,2,3],最大值 3
示例 2:
输入:n = 2
输出:1
解释:根据规则,nums[0]、nums[1] 和 nums[2] 之中的最大值是 1
示例 3:
输入:n = 3
输出:2
解释:根据规则,nums[0]、nums[1]、nums[2] 和 nums[3] 之中的最大值是 2
提示:
0 <= n <= 100
解法
1 | func getMaximumGenerated(n int) int { |
5562. 字符频次唯一的最小删除次数[中等]
如果字符串 s 中 不存在 两个不同字符 频次 相同的情况,就称 s 是 优质字符串 。
给你一个字符串 s,返回使 s 成为 优质字符串 需要删除的 最小 字符数。
字符串中字符的 频次 是该字符在字符串中的出现次数。例如,在字符串 “aab” 中,’a’ 的频次是 2,而 ‘b’ 的频次是 1 。
示例 1:
输入:s = “aab”
输出:0
解释:s 已经是优质字符串。
示例 2:
输入:s = “aaabbbcc”
输出:2
解释:可以删除两个 ‘b’ , 得到优质字符串 “aaabcc” 。
另一种方式是删除一个 ‘b’ 和一个 ‘c’ ,得到优质字符串 “aaabbc” 。
示例 3:
输入:s = “ceabaacb”
输出:2
解释:可以删除两个 ‘c’ 得到优质字符串 “eabaab” 。
注意,只需要关注结果字符串中仍然存在的字符。(即,频次为 0 的字符会忽略不计。)
提示:
1 <= s.length <= 105
s 仅含小写英文字母
解法
首先,计算各个字符出现的频次。然后根据频次进行从小到大排序。
排序之后的数据,例如1,2,3,4,5.前面的没有比后面的大,优质数据。
如果出现1,2,3,4,5,7,7。这种情况,从右往左比较,7 = 7,需要将7-1达到6 7。这时候整个数据组需要考虑的最大值就是6.6再和5比较,5再和4比较。
1 | func minDeletions(s string) int { |
961. 重复 N 次的元素[简单]
在大小为 2N 的数组 A 中有 N+1 个不同的元素,其中有一个元素重复了 N 次。
返回重复了 N 次的那个元素。
示例 1:
输入:[1,2,3,3]
输出:3
示例 2:
输入:[2,1,2,5,3,2]
输出:2
示例 3:
输入:[5,1,5,2,5,3,5,4]
输出:5
提示:
4 <= A.length <= 10000
0 <= A[i] < 10000
A.length 为偶数
解法
1 | func repeatedNTimes(A []int) int { |
953. 验证外星语词典[简单]
某种外星语也使用英文小写字母,但可能顺序 order 不同。字母表的顺序(order)是一些小写字母的排列。
给定一组用外星语书写的单词 words,以及其字母表的顺序 order,只有当给定的单词在这种外星语中按字典序排列时,返回 true;否则,返回 false。
示例 1:
输入:words = [“hello”,”leetcode”], order = “hlabcdefgijkmnopqrstuvwxyz”
输出:true
解释:在该语言的字母表中,’h’ 位于 ‘l’ 之前,所以单词序列是按字典序排列的。
示例 2:
输入:words = [“word”,”world”,”row”], order = “worldabcefghijkmnpqstuvxyz”
输出:false
解释:在该语言的字母表中,’d’ 位于 ‘l’ 之后,那么 words[0] > words[1],因此单词序列不是按字典序排列的。
示例 3:
输入:words = [“apple”,”app”], order = “abcdefghijklmnopqrstuvwxyz”
输出:false
解释:当前三个字符 “app” 匹配时,第二个字符串相对短一些,然后根据词典编纂规则 “apple” > “app”,因为 ‘l’ > ‘∅’,其中 ‘∅’ 是空白字符,定义为比任何其他字符都小(更多信息)。
提示:
1 <= words.length <= 100
1 <= words[i].length <= 20
order.length == 26
在 words[i] 和 order 中的所有字符都是英文小写字母。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/verifying-an-alien-dictionary
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func isAlienSorted(words []string, order string) bool { |
970. 强整数[简单]
给定两个正整数 x 和 y,如果某一整数等于 x^i + y^j,其中整数 i >= 0 且 j >= 0,那么我们认为该整数是一个强整数。
返回值小于或等于 bound 的所有强整数组成的列表。
你可以按任何顺序返回答案。在你的回答中,每个值最多出现一次。
示例 1:
输入:x = 2, y = 3, bound = 10
输出:[2,3,4,5,7,9,10]
解释:
2 = 2^0 + 3^0
3 = 2^1 + 3^0
4 = 2^0 + 3^1
5 = 2^1 + 3^1
7 = 2^2 + 3^1
9 = 2^3 + 3^0
10 = 2^0 + 3^2
示例 2:
输入:x = 3, y = 5, bound = 15
输出:[2,4,6,8,10,14]
提示:
1 <= x <= 100
1 <= y <= 100
0 <= bound <= 10^6
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/powerful-integers
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func powerfulIntegers(x int, y int, bound int) []int { |
1002. 查找常用字符[简单]
给定仅有小写字母组成的字符串数组 A,返回列表中的每个字符串中都显示的全部字符(包括重复字符)组成的列表。例如,如果一个字符在每个字符串中出现 3 次,但不是 4 次,则需要在最终答案中包含该字符 3 次。
你可以按任意顺序返回答案。
示例 1:
输入:[“bella”,”label”,”roller”]
输出:[“e”,”l”,”l”]
示例 2:
输入:[“cool”,”lock”,”cook”]
输出:[“c”,”o”]
提示:
1 <= A.length <= 100
1 <= A[i].length <= 100
A[i][j] 是小写字母
通过次数45,781提交次数61,532
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/find-common-characters
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func commonChars(A []string) []string { |
1160. 拼写单词[简单]
给你一份『词汇表』(字符串数组) words 和一张『字母表』(字符串) chars。
假如你可以用 chars 中的『字母』(字符)拼写出 words 中的某个『单词』(字符串),那么我们就认为你掌握了这个单词。
注意:每次拼写(指拼写词汇表中的一个单词)时,chars 中的每个字母都只能用一次。
返回词汇表 words 中你掌握的所有单词的 长度之和。
示例 1:
输入:words = [“cat”,”bt”,”hat”,”tree”], chars = “atach”
输出:6
解释:
可以形成字符串 “cat” 和 “hat”,所以答案是 3 + 3 = 6。
示例 2:
输入:words = [“hello”,”world”,”leetcode”], chars = “welldonehoneyr”
输出:10
解释:
可以形成字符串 “hello” 和 “world”,所以答案是 5 + 5 = 10。
提示:
1 <= words.length <= 1000
1 <= words[i].length, chars.length <= 100
所有字符串中都仅包含小写英文字母
通过次数49,812提交次数72,556
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/find-words-that-can-be-formed-by-characters
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func countCharacters(words []string, chars string) int { |
1078. Bigram 分词[简单]
给出第一个词 first 和第二个词 second,考虑在某些文本 text 中可能以 “first second third” 形式出现的情况,其中 second 紧随 first 出现,third 紧随 second 出现。
对于每种这样的情况,将第三个词 “third” 添加到答案中,并返回答案。
示例 1:
输入:text = “alice is a good girl she is a good student”, first = “a”, second = “good”
输出:[“girl”,”student”]
示例 2:
输入:text = “we will we will rock you”, first = “we”, second = “will”
输出:[“we”,”rock”]
提示:
1 <= text.length <= 1000
text 由一些用空格分隔的单词组成,每个单词都由小写英文字母组成
1 <= first.length, second.length <= 10
first 和 second 由小写英文字母组成
通过次数8,434提交次数13,664
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/occurrences-after-bigram
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func findOcurrences(text string, first string, second string) []string { |
1189. “气球” 的最大数量[简单]
给你一个字符串 text,你需要使用 text 中的字母来拼凑尽可能多的单词 “balloon”(气球)。
字符串 text 中的每个字母最多只能被使用一次。请你返回最多可以拼凑出多少个单词 “balloon”。
示例 1:
输入:text = “nlaebolko”
输出:1
示例 2:
输入:text = “loonbalxballpoon”
输出:2
示例 3:
输入:text = “leetcode”
输出:0
提示:
1 <= text.length <= 10^4
text 全部由小写英文字母组成
通过次数14,925提交次数23,392
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/maximum-number-of-balloons
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func maxNumberOfBalloons(text string) int { |
1207. 独一无二的出现次数[简单]
给你一个整数数组 arr,请你帮忙统计数组中每个数的出现次数。
如果每个数的出现次数都是独一无二的,就返回 true;否则返回 false。
示例 1:
输入:arr = [1,2,2,1,1,3]
输出:true
解释:在该数组中,1 出现了 3 次,2 出现了 2 次,3 只出现了 1 次。没有两个数的出现次数相同。
示例 2:
输入:arr = [1,2]
输出:false
示例 3:
输入:arr = [-3,0,1,-3,1,1,1,-3,10,0]
输出:true
提示:
1 <= arr.length <= 1000
-1000 <= arr[i] <= 1000
通过次数50,961提交次数69,561
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/unique-number-of-occurrences
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func uniqueOccurrences(arr []int) bool { |
面试题 01.04. 回文排列[简单]
给定一个字符串,编写一个函数判定其是否为某个回文串的排列之一。
回文串是指正反两个方向都一样的单词或短语。排列是指字母的重新排列。
回文串不一定是字典当中的单词。
示例1:
输入:”tactcoa”
输出:true(排列有”tacocat”、”atcocta”,等等)
通过次数20,609提交次数37,87
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/palindrome-permutation-lcci
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func canPermutePalindrome(s string) bool { |
1539. 第 k 个缺失的正整数[简单]
给你一个 严格升序排列 的正整数数组 arr 和一个整数 k 。
请你找到这个数组里第 k 个缺失的正整数。
示例 1:
输入:arr = [2,3,4,7,11], k = 5
输出:9
解释:缺失的正整数包括 [1,5,6,8,9,10,12,13,…] 。第 5 个缺失的正整数为 9 。
示例 2:
输入:arr = [1,2,3,4], k = 2
输出:6
解释:缺失的正整数包括 [5,6,7,…] 。第 2 个缺失的正整数为 6 。
提示:
1 <= arr.length <= 1000
1 <= arr[i] <= 1000
1 <= k <= 1000
对于所有 1 <= i < j <= arr.length 的 i 和 j 满足 arr[i] < arr[j]
通过次数6,505提交次数12,027
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/kth-missing-positive-number
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func findKthPositive(arr []int, k int) int { |
1365. 有多少小于当前数字的数字[简单]
给你一个数组 nums,对于其中每个元素 nums[i],请你统计数组中比它小的所有数字的数目。
换而言之,对于每个 nums[i] 你必须计算出有效的 j 的数量,其中 j 满足 j != i 且 nums[j] < nums[i] 。
以数组形式返回答案。
示例 1:
输入:nums = [8,1,2,2,3]
输出:[4,0,1,1,3]
解释:
对于 nums[0]=8 存在四个比它小的数字:(1,2,2 和 3)。
对于 nums[1]=1 不存在比它小的数字。
对于 nums[2]=2 存在一个比它小的数字:(1)。
对于 nums[3]=2 存在一个比它小的数字:(1)。
对于 nums[4]=3 存在三个比它小的数字:(1,2 和 2)。
示例 2:
输入:nums = [6,5,4,8]
输出:[2,1,0,3]
示例 3:
输入:nums = [7,7,7,7]
输出:[0,0,0,0]
提示:
2 <= nums.length <= 500
0 <= nums[i] <= 100
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/how-many-numbers-are-smaller-than-the-current-number
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func smallerNumbersThanCurrent(nums []int) []int { |
1512. 好数对的数目[简单]
给你一个整数数组 nums 。
如果一组数字 (i,j) 满足 nums[i] == nums[j] 且 i < j ,就可以认为这是一组 好数对 。
返回好数对的数目。
示例 1:
输入:nums = [1,2,3,1,1,3]
输出:4
解释:有 4 组好数对,分别是 (0,3), (0,4), (3,4), (2,5) ,下标从 0 开始
示例 2:
输入:nums = [1,1,1,1]
输出:6
解释:数组中的每组数字都是好数对
示例 3:
输入:nums = [1,2,3]
输出:0
提示:
1 <= nums.length <= 100
1 <= nums[i] <= 100
通过次数33,037提交次数38,800
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/number-of-good-pairs
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func numIdenticalPairs(nums []int) int { |
1625. 执行操作后字典序最小的字符串[中等]
给你一个字符串 s 以及两个整数 a 和 b 。其中,字符串 s 的长度为偶数,且仅由数字 0 到 9 组成。
你可以在 s 上按任意顺序多次执行下面两个操作之一:
累加:将 a 加到 s 中所有下标为奇数的元素上(下标从 0 开始)。数字一旦超过 9 就会变成 0,如此循环往复。例如,s = “3456” 且 a = 5,则执行此操作后 s 变成 “3951”。
轮转:将 s 向右轮转 b 位。例如,s = “3456” 且 b = 1,则执行此操作后 s 变成 “6345”。
请你返回在 s 上执行上述操作任意次后可以得到的 字典序最小 的字符串。
如果两个字符串长度相同,那么字符串 a 字典序比字符串 b 小可以这样定义:在 a 和 b 出现不同的第一个位置上,字符串 a 中的字符出现在字母表中的时间早于 b 中的对应字符。例如,”0158” 字典序比 “0190” 小,因为不同的第一个位置是在第三个字符,显然 ‘5’ 出现在 ‘9’ 之前。
示例 1:
输入:s = “5525”, a = 9, b = 2
输出:”2050”
解释:执行操作如下:
初态:”5525”
轮转:”2555”
累加:”2454”
累加:”2353”
轮转:”5323”
累加:”5222”
累加:”5121”
轮转:”2151”
累加:”2050”
无法获得字典序小于 “2050” 的字符串。
示例 2:
输入:s = “74”, a = 5, b = 1
输出:”24”
解释:执行操作如下:
初态:”74”
轮转:”47”
累加:”42”
轮转:”24”
无法获得字典序小于 “24” 的字符串。
示例 3:
输入:s = “0011”, a = 4, b = 2
输出:”0011”
解释:无法获得字典序小于 “0011” 的字符串。
示例 4:
输入:s = “43987654”, a = 7, b = 3
输出:”00553311”
提示:
2 <= s.length <= 100
s.length 是偶数
s 仅由数字 0 到 9 组成
1 <= a <= 9
1 <= b <= s.length - 1
通过次数2,071提交次数4,004
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/lexicographically-smallest-string-after-applying-operations
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | // 累加偶数位操作 |
228. 汇总区间[简单]
给定一个无重复元素的有序整数数组 nums 。
返回 恰好覆盖数组中所有数字 的 最小有序 区间范围列表。也就是说,nums 的每个元素都恰好被某个区间范围所覆盖,并且不存在属于某个范围但不属于 nums 的数字 x 。
列表中的每个区间范围 [a,b] 应该按如下格式输出:
“a->b” ,如果 a != b
“a” ,如果 a == b
示例 1:
输入:nums = [0,1,2,4,5,7]
输出:[“0->2”,”4->5”,”7”]
解释:区间范围是:
[0,2] –> “0->2”
[4,5] –> “4->5”
[7,7] –> “7”
示例 2:
输入:nums = [0,2,3,4,6,8,9]
输出:[“0”,”2->4”,”6”,”8->9”]
解释:区间范围是:
[0,0] –> “0”
[2,4] –> “2->4”
[6,6] –> “6”
[8,9] –> “8->9”
示例 3:
输入:nums = []
输出:[]
示例 4:
输入:nums = [-1]
输出:[“-1”]
示例 5:
输入:nums = [0]
输出:[“0”]
提示:
0 <= nums.length <= 20
-231 <= nums[i] <= 231 - 1
nums 中的所有值都 互不相同
通过次数16,046提交次数29,801
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/summary-ranges
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func summaryRanges(nums []int) []string { |
1122. 数组的相对排序[简单]
给你两个数组,arr1 和 arr2,
arr2 中的元素各不相同
arr2 中的每个元素都出现在 arr1 中
对 arr1 中的元素进行排序,使 arr1 中项的相对顺序和 arr2 中的相对顺序相同。未在 arr2 中出现过的元素需要按照升序放在 arr1 的末尾。
示例:
输入:arr1 = [2,3,1,3,2,4,6,7,9,2,19], arr2 = [2,1,4,3,9,6]
输出:[2,2,2,1,4,3,3,9,6,7,19]
提示:
arr1.length, arr2.length <= 1000
0 <= arr1[i], arr2[i] <= 1000
arr2 中的元素 arr2[i] 各不相同
arr2 中的每个元素 arr2[i] 都出现在 arr1 中
通过次数33,354提交次数48,291
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/relative-sort-array
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func relativeSortArray(arr1 []int, arr2 []int) []int { |
5550. 拆炸弹[简单]
你有一个炸弹需要拆除,时间紧迫!你的情报员会给你一个长度为 n 的 循环 数组 code 以及一个密钥 k 。
为了获得正确的密码,你需要替换掉每一个数字。所有数字会 同时 被替换。
如果 k > 0 ,将第 i 个数字用 接下来 k 个数字之和替换。
如果 k < 0 ,将第 i 个数字用 之前 k 个数字之和替换。
如果 k == 0 ,将第 i 个数字用 0 替换。
由于 code 是循环的, code[n-1] 下一个元素是 code[0] ,且 code[0] 前一个元素是 code[n-1] 。
给你 循环 数组 code 和整数密钥 k ,请你返回解密后的结果来拆除炸弹!
示例 1:
输入:code = [5,7,1,4], k = 3
输出:[12,10,16,13]
解释:每个数字都被接下来 3 个数字之和替换。解密后的密码为 [7+1+4, 1+4+5, 4+5+7, 5+7+1]。注意到数组是循环连接的。
示例 2:
输入:code = [1,2,3,4], k = 0
输出:[0,0,0,0]
解释:当 k 为 0 时,所有数字都被 0 替换。
示例 3:
输入:code = [2,4,9,3], k = -2
输出:[12,5,6,13]
解释:解密后的密码为 [3+9, 2+3, 4+2, 9+4] 。注意到数组是循环连接的。如果 k 是负数,那么和为 之前 的数字。
提示:
n == code.length
1 <= n <= 100
1 <= code[i] <= 100
-(n - 1) <= k <= n - 1
解法
1 | func decrypt(code []int, k int) []int { |
5551. 使字符串平衡的最少删除次数[中等]
给你一个字符串 s ,它仅包含字符 ‘a’ 和 ‘b’ 。
你可以删除 s 中任意数目的字符,使得 s 平衡 。我们称 s 平衡的 当不存在下标对 (i,j) 满足 i < j 且 s[i] = ‘b’ 同时 s[j]= ‘a’ 。
请你返回使 s 平衡 的 最少 删除次数。
示例 1:
输入:s = “aababbab”
输出:2
解释:你可以选择以下任意一种方案:
下标从 0 开始,删除第 2 和第 6 个字符(”aababbab” -> “aaabbb”),
下标从 0 开始,删除第 3 和第 6 个字符(”aababbab” -> “aabbbb”)。
示例 2:
输入:s = “bbaaaaabb”
输出:2
解释:唯一的最优解是删除最前面两个字符。
提示:
1 <= s.length <= 105
s[i] 要么是 ‘a’ 要么是 ‘b’ 。
通过次数976提交次数2,651
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/minimum-deletions-to-make-string-balanced
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
从0到n建立分割点,分割点左边全是a,分割点右边全是b。然后计算删除最小分割点。
1 | func minimumDeletions(s string) int { |
代码会超时,因为每个分割点都需要重新计算之前计算过的值。使用备忘录来减少计算量。
1 | func minimumDeletions(s string) int { |
402. 移掉K位数字
给定一个以字符串表示的非负整数 num,移除这个数中的 k 位数字,使得剩下的数字最小。
注意:
num 的长度小于 10002 且 ≥ k。
num 不会包含任何前导零。
示例 1 :
输入: num = “1432219”, k = 3
输出: “1219”
解释: 移除掉三个数字 4, 3, 和 2 形成一个新的最小的数字 1219。
示例 2 :
输入: num = “10200”, k = 1
输出: “200”
解释: 移掉首位的 1 剩下的数字为 200. 注意输出不能有任何前导零。
示例 3 :
输入: num = “10”, k = 2
输出: “0”
解释: 从原数字移除所有的数字,剩余为空就是0。
通过次数37,724提交次数120,200
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/remove-k-digits
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
由于可以删除的次数有限,每删除一个字符,数字的位数就降低一位。所以,删除的时候肯定要在高位删除,怎么删除?如果当前的字符大于后面的字符,删除该字符的成效是最高的。
1 | func removeKdigits(num string, k int) string { |
3. 无重复字符的最长子串[简单]
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: “abcabcbb”
输出: 3
解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
示例 2:
输入: “bbbbb”
输出: 1
解释: 因为无重复字符的最长子串是 “b”,所以其长度为 1。
示例 3:
输入: “pwwkew”
输出: 3
解释: 因为无重复字符的最长子串是 “wke”,所以其长度为 3。
请注意,你的答案必须是 子串 的长度,”pwke” 是一个子序列,不是子串。
通过次数726,574提交次数2,026,880
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/longest-substring-without-repeating-characters
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func lengthOfLongestSubstring(s string) int { |
1030. 距离顺序排列矩阵单元格[简单]
给出 R 行 C 列的矩阵,其中的单元格的整数坐标为 (r, c),满足 0 <= r < R 且 0 <= c < C。
另外,我们在该矩阵中给出了一个坐标为 (r0, c0) 的单元格。
返回矩阵中的所有单元格的坐标,并按到 (r0, c0) 的距离从最小到最大的顺序排,其中,两单元格(r1, c1) 和 (r2, c2) 之间的距离是曼哈顿距离,|r1 - r2| + |c1 - c2|。(你可以按任何满足此条件的顺序返回答案。)
示例 1:
输入:R = 1, C = 2, r0 = 0, c0 = 0
输出:[[0,0],[0,1]]
解释:从 (r0, c0) 到其他单元格的距离为:[0,1]
示例 2:
输入:R = 2, C = 2, r0 = 0, c0 = 1
输出:[[0,1],[0,0],[1,1],[1,0]]
解释:从 (r0, c0) 到其他单元格的距离为:[0,1,1,2]
[[0,1],[1,1],[0,0],[1,0]] 也会被视作正确答案。
示例 3:
输入:R = 2, C = 3, r0 = 1, c0 = 2
输出:[[1,2],[0,2],[1,1],[0,1],[1,0],[0,0]]
解释:从 (r0, c0) 到其他单元格的距离为:[0,1,1,2,2,3]
其他满足题目要求的答案也会被视为正确,例如 [[1,2],[1,1],[0,2],[1,0],[0,1],[0,0]]。
提示:
1 <= R <= 100
1 <= C <= 100
0 <= r0 < R
0 <= c0 < C
通过次数30,037提交次数42,187
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/matrix-cells-in-distance-order
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func abs(x int) int { |
15. 三数之和[中等]
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有满足条件且不重复的三元组。
注意:答案中不可以包含重复的三元组。
示例:
给定数组 nums = [-1, 0, 1, 2, -1, -4],
满足要求的三元组集合为:
[
[-1, 0, 1],
[-1, -1, 2]
]
通过次数365,190提交次数1,215,505
在真实的面试中遇到过这道题?
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/3sum
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func threeSum(nums []int) [][]int { |
面试题 17.16. 按摩师[简单]
一个有名的按摩师会收到源源不断的预约请求,每个预约都可以选择接或不接。在每次预约服务之间要有休息时间,因此她不能接受相邻的预约。给定一个预约请求序列,替按摩师找到最优的预约集合(总预约时间最长),返回总的分钟数。
注意:本题相对原题稍作改动
示例 1:
输入: [1,2,3,1]
输出: 4
解释: 选择 1 号预约和 3 号预约,总时长 = 1 + 3 = 4。
示例 2:
输入: [2,7,9,3,1]
输出: 12
解释: 选择 1 号预约、 3 号预约和 5 号预约,总时长 = 2 + 9 + 1 = 12。
示例 3:
输入: [2,1,4,5,3,1,1,3]
输出: 12
解释: 选择 1 号预约、 3 号预约、 5 号预约和 8 号预约,总时长 = 2 + 4 + 3 + 3 = 12。
通过次数41,505提交次数78,530
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/the-masseuse-lcci
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func massage(nums []int) int { |
剑指 Offer 42. 连续子数组的最大和[简单]
输入一个整型数组,数组中的一个或连续多个整数组成一个子数组。求所有子数组的和的最大值。
要求时间复杂度为O(n)。
示例1:
输入: nums = [-2,1,-3,4,-1,2,1,-5,4]
输出: 6
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
提示:
1 <= arr.length <= 10^5
-100 <= arr[i] <= 100
注意:本题与主站 53 题相同:https://leetcode-cn.com/problems/maximum-subarray/
通过次数83,080提交次数139,064
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/lian-xu-zi-shu-zu-de-zui-da-he-lcof
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func maxSubArray(nums []int) int { |
面试题 08.01. 三步问题[简单]
三步问题。有个小孩正在上楼梯,楼梯有n阶台阶,小孩一次可以上1阶、2阶或3阶。实现一种方法,计算小孩有多少种上楼梯的方式。结果可能很大,你需要对结果模1000000007。
示例1:
输入:n = 3
输出:4
说明: 有四种走法
示例2:
输入:n = 5
输出:13
提示:
n范围在[1, 1000000]之间
通过次数22,922提交次数64,829
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/three-steps-problem-lcci
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func waysToStep(n int) int { |
392. 判断子序列[简单]
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
你可以认为 s 和 t 中仅包含英文小写字母。字符串 t 可能会很长(长度 ~= 500,000),而 s 是个短字符串(长度 <=100)。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,”ace”是”abcde”的一个子序列,而”aec”不是)。
示例 1:
s = “abc”, t = “ahbgdc”
返回 true.
示例 2:
s = “axc”, t = “ahbgdc”
返回 false.
后续挑战 :
如果有大量输入的 S,称作S1, S2, … , Sk 其中 k >= 10亿,你需要依次检查它们是否为 T 的子序列。在这种情况下,你会怎样改变代码?
致谢:
特别感谢 @pbrother 添加此问题并且创建所有测试用例。
通过次数95,681提交次数189,045
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/is-subsequence
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func isSubsequence(s string, t string) bool { |
746. 使用最小花费爬楼梯[简单]
数组的每个索引作为一个阶梯,第 i个阶梯对应着一个非负数的体力花费值 costi。
每当你爬上一个阶梯你都要花费对应的体力花费值,然后你可以选择继续爬一个阶梯或者爬两个阶梯。
您需要找到达到楼层顶部的最低花费。在开始时,你可以选择从索引为 0 或 1 的元素作为初始阶梯。
示例 1:
输入: cost = [10, 15, 20]
输出: 15
解释: 最低花费是从cost[1]开始,然后走两步即可到阶梯顶,一共花费15。
示例 2:
输入: cost = [1, 100, 1, 1, 1, 100, 1, 1, 100, 1]
输出: 6
解释: 最低花费方式是从cost[0]开始,逐个经过那些1,跳过cost[3],一共花费6。
注意:
cost 的长度将会在 [2, 1000]。
每一个 cost[i] 将会是一个Integer类型,范围为 [0, 999]。
通过次数49,537提交次数99,055
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/min-cost-climbing-stairs
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 |
|
303. 区域和检索 - 数组不可变[检索]
给定一个整数数组 nums,求出数组从索引 i 到 j(i ≤ j)范围内元素的总和,包含 i、j 两点。
实现 NumArray 类:
NumArray(int[] nums) 使用数组 nums 初始化对象
int sumRange(int i, int j) 返回数组 nums 从索引 i 到 j(i ≤ j)范围内元素的总和,包含 i、j 两点(也就是 sum(nums[i], nums[i + 1], … , nums[j]))
示例:
输入:
[“NumArray”, “sumRange”, “sumRange”, “sumRange”]
[[[-2, 0, 3, -5, 2, -1]], [0, 2], [2, 5], [0, 5]]
输出:
[null, 1, -1, -3]
解释:
NumArray numArray = new NumArray([-2, 0, 3, -5, 2, -1]);
numArray.sumRange(0, 2); // return 1 ((-2) + 0 + 3)
numArray.sumRange(2, 5); // return -1 (3 + (-5) + 2 + (-1))
numArray.sumRange(0, 5); // return -3 ((-2) + 0 + 3 + (-5) + 2 + (-1))
提示:
0 <= nums.length <= 104
-105 <= nums[i] <= 105
0 <= i <= j < nums.length
最多调用 104 次 sumRange 方法
通过次数59,723提交次数93,547
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/range-sum-query-immutable
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 |
|
198. 打家劫舍[简单]
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
示例 1:
输入:[1,2,3,1]
输出:4
解释:偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。
偷窃到的最高金额 = 1 + 3 = 4 。
示例 2:
输入:[2,7,9,3,1]
输出:12
解释:偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。
偷窃到的最高金额 = 2 + 9 + 1 = 12 。
提示:
0 <= nums.length <= 100
0 <= nums[i] <= 400
通过次数209,567提交次数445,961
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/house-robber
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func rob(nums []int) int { |
18. 四数之和[简单]
给定一个包含 n 个整数的数组 nums 和一个目标值 target,判断 nums 中是否存在四个元素 a,b,c 和 d ,使得 a + b + c + d 的值与 target 相等?找出所有满足条件且不重复的四元组。
注意:
答案中不可以包含重复的四元组。
示例:
给定数组 nums = [1, 0, -1, 0, -2, 2],和 target = 0。
满足要求的四元组集合为:
[
[-1, 0, 0, 1],
[-2, -1, 1, 2],
[-2, 0, 0, 2]
]
通过次数136,237提交次数346,498
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/4sum
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func fourSum(nums []int, target int) [][]int { |
148. 排序链表[简单]
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
进阶:
你可以在 O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序吗?
示例 1:
输入:head = [4,2,1,3]
输出:[1,2,3,4]
示例 2:
输入:head = [-1,5,3,4,0]
输出:[-1,0,3,4,5]
示例 3:
输入:head = []
输出:[]
提示:
链表中节点的数目在范围 [0, 5 * 104] 内
-105 <= Node.val <= 105
通过次数117,556提交次数173,664
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/sort-list
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | /** |
剑指 Offer 64. 求1+2+…+n[中等]
求 1+2+…+n ,要求不能使用乘除法、for、while、if、else、switch、case等关键字及条件判断语句(A?B:C)。
示例 1:
输入: n = 3
输出: 6
示例 2:
输入: n = 9
输出: 45
限制:
1 <= n <= 10000
通过次数75,194提交次数88,313
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/qiu-12n-lcof
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func sumNums(n int) int { |
151. 翻转字符串里的单词[中等]
给定一个字符串,逐个翻转字符串中的每个单词。
说明:
无空格字符构成一个 单词 。
输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
示例 1:
输入:”the sky is blue”
输出:”blue is sky the”
示例 2:
输入:” hello world! “
输出:”world! hello”
解释:输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
示例 3:
输入:”a good example”
输出:”example good a”
解释:如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
示例 4:
输入:s = “ Bob Loves Alice “
输出:”Alice Loves Bob”
示例 5:
输入:s = “Alice does not even like bob”
输出:”bob like even not does Alice”
提示:
1 <= s.length <= 104
s 包含英文大小写字母、数字和空格 ‘ ‘
s 中 至少存在一个 单词
进阶:
请尝试使用 O(1) 额外空间复杂度的原地解法。
通过次数104,729提交次数237,112
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/reverse-words-in-a-string
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func reverseWords(s string) string { |
452. 用最少数量的箭引爆气球[简单]
在二维空间中有许多球形的气球。对于每个气球,提供的输入是水平方向上,气球直径的开始和结束坐标。由于它是水平的,所以纵坐标并不重要,因此只要知道开始和结束的横坐标就足够了。开始坐标总是小于结束坐标。
一支弓箭可以沿着 x 轴从不同点完全垂直地射出。在坐标 x 处射出一支箭,若有一个气球的直径的开始和结束坐标为 xstart,xend, 且满足 xstart ≤ x ≤ xend,则该气球会被引爆。可以射出的弓箭的数量没有限制。 弓箭一旦被射出之后,可以无限地前进。我们想找到使得所有气球全部被引爆,所需的弓箭的最小数量。
给你一个数组 points ,其中 points [i] = [xstart,xend] ,返回引爆所有气球所必须射出的最小弓箭数。
示例 1:
输入:points = [[10,16],[2,8],[1,6],[7,12]]
输出:2
解释:对于该样例,x = 6 可以射爆 [2,8],[1,6] 两个气球,以及 x = 11 射爆另外两个气球
示例 2:
输入:points = [[1,2],[3,4],[5,6],[7,8]]
输出:4
示例 3:
输入:points = [[1,2],[2,3],[3,4],[4,5]]
输出:2
示例 4:
输入:points = [[1,2]]
输出:1
示例 5:
输入:points = [[2,3],[2,3]]
输出:1
提示:
0 <= points.length <= 104
points[i].length == 2
-231 <= xstart < xend <= 231 - 1
通过次数46,011提交次数90,356
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/minimum-number-of-arrows-to-burst-balloons
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func findMinArrowShots(points [][]int) int { |
1576. 替换所有的问号[简单]
给你一个仅包含小写英文字母和 ‘?’ 字符的字符串 s,请你将所有的 ‘?’ 转换为若干小写字母,使最终的字符串不包含任何 连续重复 的字符。
注意:你 不能 修改非 ‘?’ 字符。
题目测试用例保证 除 ‘?’ 字符 之外,不存在连续重复的字符。
在完成所有转换(可能无需转换)后返回最终的字符串。如果有多个解决方案,请返回其中任何一个。可以证明,在给定的约束条件下,答案总是存在的。
示例 1:
输入:s = “?zs”
输出:”azs”
解释:该示例共有 25 种解决方案,从 “azs” 到 “yzs” 都是符合题目要求的。只有 “z” 是无效的修改,因为字符串 “zzs” 中有连续重复的两个 ‘z’ 。
示例 2:
输入:s = “ubv?w”
输出:”ubvaw”
解释:该示例共有 24 种解决方案,只有替换成 “v” 和 “w” 不符合题目要求。因为 “ubvvw” 和 “ubvww” 都包含连续重复的字符。
示例 3:
输入:s = “j?qg??b”
输出:”jaqgacb”
示例 4:
输入:s = “??yw?ipkj?”
输出:”acywaipkja”
提示:
1 <= s.length <= 100
s 仅包含小写英文字母和 ‘?’ 字符
通过次数9,573提交次数19,975
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/replace-all-s-to-avoid-consecutive-repeating-characters
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func modifyString(s string) string { |
222. 完全二叉树的节点个数[中等]
给出一个完全二叉树,求出该树的节点个数。
说明:
完全二叉树的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2h 个节点。
示例:
输入:
1
/
2 3
/ \ /
4 5 6
输出: 6
通过次数61,729提交次数81,007
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/count-complete-tree-nodes
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func countNodes(root *TreeNode) int { |
5. 最长回文子串
给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
示例 1:
输入: “babad”
输出: “bab”
注意: “aba” 也是一个有效答案。
示例 2:
输入: “cbbd”
输出: “bb”
通过次数424,490提交次数1,310,495
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/longest-palindromic-substring
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
暴力解法-超时
1 |
|
动态规划
1 | func longestPalindrome(s string) string { |
1370. 上升下降字符串[简单]
给你一个字符串 s ,请你根据下面的算法重新构造字符串:
从 s 中选出 最小 的字符,将它 接在 结果字符串的后面。
从 s 剩余字符中选出 最小 的字符,且该字符比上一个添加的字符大,将它 接在 结果字符串后面。
重复步骤 2 ,直到你没法从 s 中选择字符。
从 s 中选出 最大 的字符,将它 接在 结果字符串的后面。
从 s 剩余字符中选出 最大 的字符,且该字符比上一个添加的字符小,将它 接在 结果字符串后面。
重复步骤 5 ,直到你没法从 s 中选择字符。
重复步骤 1 到 6 ,直到 s 中所有字符都已经被选过。
在任何一步中,如果最小或者最大字符不止一个 ,你可以选择其中任意一个,并将其添加到结果字符串。
请你返回将 s 中字符重新排序后的 结果字符串 。
示例 1:
输入:s = “aaaabbbbcccc”
输出:”abccbaabccba”
解释:第一轮的步骤 1,2,3 后,结果字符串为 result = “abc”
第一轮的步骤 4,5,6 后,结果字符串为 result = “abccba”
第一轮结束,现在 s = “aabbcc” ,我们再次回到步骤 1
第二轮的步骤 1,2,3 后,结果字符串为 result = “abccbaabc”
第二轮的步骤 4,5,6 后,结果字符串为 result = “abccbaabccba”
示例 2:
输入:s = “rat”
输出:”art”
解释:单词 “rat” 在上述算法重排序以后变成 “art”
示例 3:
输入:s = “leetcode”
输出:”cdelotee”
示例 4:
输入:s = “ggggggg”
输出:”ggggggg”
示例 5:
输入:s = “spo”
输出:”ops”
提示:
1 <= s.length <= 500
s 只包含小写英文字母。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/increasing-decreasing-string
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 |
|
187. 重复的DNA序列[中等]
所有 DNA 都由一系列缩写为 ‘A’,’C’,’G’ 和 ‘T’ 的核苷酸组成,例如:”ACGAATTCCG”。在研究 DNA 时,识别 DNA 中的重复序列有时会对研究非常有帮助。
编写一个函数来找出所有目标子串,目标子串的长度为 10,且在 DNA 字符串 s 中出现次数超过一次。
示例 1:
输入:s = “AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT”
输出:[“AAAAACCCCC”,”CCCCCAAAAA”]
示例 2:
输入:s = “AAAAAAAAAAAAA”
输出:[“AAAAAAAAAA”]
提示:
0 <= s.length <= 105
s[i] 为 ‘A’、’C’、’G’ 或 ‘T’
通过次数25,520提交次数55,859
在真实的面试中遇到过这道题?
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/repeated-dna-sequences
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func findRepeatedDnaSequences(s string) []string { |
49. 字母异位词分组[中等]
给定一个字符串数组,将字母异位词组合在一起。字母异位词指字母相同,但排列不同的字符串。
示例:
输入: [“eat”, “tea”, “tan”, “ate”, “nat”, “bat”]
输出:
[
[“ate”,”eat”,”tea”],
[“nat”,”tan”],
[“bat”]
]
说明:
所有输入均为小写字母。
不考虑答案输出的顺序。
通过次数121,801提交次数190,239
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/group-anagrams
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 |
|
36. 有效的数独[中等]
判断一个 9x9 的数独是否有效。只需要根据以下规则,验证已经填入的数字是否有效即可。
数字 1-9 在每一行只能出现一次。
数字 1-9 在每一列只能出现一次。
数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。
上图是一个部分填充的有效的数独。
数独部分空格内已填入了数字,空白格用 ‘.’ 表示。
示例 1:
输入:
[
[“5”,”3”,”.”,”.”,”7”,”.”,”.”,”.”,”.”],
[“6”,”.”,”.”,”1”,”9”,”5”,”.”,”.”,”.”],
[“.”,”9”,”8”,”.”,”.”,”.”,”.”,”6”,”.”],
[“8”,”.”,”.”,”.”,”6”,”.”,”.”,”.”,”3”],
[“4”,”.”,”.”,”8”,”.”,”3”,”.”,”.”,”1”],
[“7”,”.”,”.”,”.”,”2”,”.”,”.”,”.”,”6”],
[“.”,”6”,”.”,”.”,”.”,”.”,”2”,”8”,”.”],
[“.”,”.”,”.”,”4”,”1”,”9”,”.”,”.”,”5”],
[“.”,”.”,”.”,”.”,”8”,”.”,”.”,”7”,”9”]
]
输出: true
示例 2:
输入:
[
[“8”,”3”,”.”,”.”,”7”,”.”,”.”,”.”,”.”],
[“6”,”.”,”.”,”1”,”9”,”5”,”.”,”.”,”.”],
[“.”,”9”,”8”,”.”,”.”,”.”,”.”,”6”,”.”],
[“8”,”.”,”.”,”.”,”6”,”.”,”.”,”.”,”3”],
[“4”,”.”,”.”,”8”,”.”,”3”,”.”,”.”,”1”],
[“7”,”.”,”.”,”.”,”2”,”.”,”.”,”.”,”6”],
[“.”,”6”,”.”,”.”,”.”,”.”,”2”,”8”,”.”],
[“.”,”.”,”.”,”4”,”1”,”9”,”.”,”.”,”5”],
[“.”,”.”,”.”,”.”,”8”,”.”,”.”,”7”,”9”]
]
输出: false
解释: 除了第一行的第一个数字从 5 改为 8 以外,空格内其他数字均与 示例1 相同。
但由于位于左上角的 3x3 宫内有两个 8 存在, 因此这个数独是无效的。
说明:
一个有效的数独(部分已被填充)不一定是可解的。
只需要根据以上规则,验证已经填入的数字是否有效即可。
给定数独序列只包含数字 1-9 和字符 ‘.’ 。
给定数独永远是 9x9 形式的。
通过次数106,340提交次数172,920
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/valid-sudoku
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func isValidSudoku(board [][]byte) bool { |
30. 串联所有单词的子串[困难]
给定一个字符串 s 和一些长度相同的单词 words。找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置。
注意子串要与 words 中的单词完全匹配,中间不能有其他字符,但不需要考虑 words 中单词串联的顺序。
示例 1:
输入:
s = “barfoothefoobarman”,
words = [“foo”,”bar”]
输出:[0,9]
解释:
从索引 0 和 9 开始的子串分别是 “barfoo” 和 “foobar” 。
输出的顺序不重要, [9,0] 也是有效答案。
示例 2:
输入:
s = “wordgoodgoodgoodbestword”,
words = [“word”,”good”,”best”,”word”]
输出:[]
通过次数49,977提交次数152,568
在真实的面试中遇到过这道题?
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/substring-with-concatenation-of-all-words
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 |
|
454. 四数相加 II[中等]
给定四个包含整数的数组列表 A , B , C , D ,计算有多少个元组 (i, j, k, l) ,使得 A[i] + B[j] + C[k] + D[l] = 0。
为了使问题简单化,所有的 A, B, C, D 具有相同的长度 N,且 0 ≤ N ≤ 500 。所有整数的范围在 -228 到 228 - 1 之间,最终结果不会超过 231 - 1 。
例如:
输入:
A = [ 1, 2]
B = [-2,-1]
C = [-1, 2]
D = [ 0, 2]
输出:
2
解释:
两个元组如下:
- (0, 0, 0, 1) -> A[0] + B[0] + C[0] + D[1] = 1 + (-2) + (-1) + 2 = 0
- (1, 1, 0, 0) -> A[1] + B[1] + C[0] + D[0] = 2 + (-1) + (-1) + 0 = 0
通过次数49,692提交次数86,457
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/4sum-ii
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func fourSumCount(A []int, B []int, C []int, D []int) int { |
617. 合并二叉树[简单]
给定两个二叉树,想象当你将它们中的一个覆盖到另一个上时,两个二叉树的一些节点便会重叠。
你需要将他们合并为一个新的二叉树。合并的规则是如果两个节点重叠,那么将他们的值相加作为节点合并后的新值,否则不为 NULL 的节点将直接作为新二叉树的节点。
示例 1:
输入:
Tree 1 Tree 2
1 2
/ \ / \
3 2 1 3
/ \ \
5 4 7
输出:
合并后的树:
3
/
4 5
/ \ \
5 4 7
注意: 合并必须从两个树的根节点开始。
通过次数109,219提交次数139,216
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/merge-two-binary-trees
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func mergeTrees(t1 *TreeNode, t2 *TreeNode) *TreeNode { |
剑指 Offer 07. 重建二叉树[中等]
输入某二叉树的前序遍历和中序遍历的结果,请重建该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。
例如,给出
前序遍历 preorder = [3,9,20,15,7]
中序遍历 inorder = [9,3,15,20,7]
返回如下的二叉树:
3 /
9 20
/
15 7
限制:
0 <= 节点个数 <= 5000
注意:本题与主站 105 题重复:https://leetcode-cn.com/problems/construct-binary-tree-from-preorder-and-inorder-traversal/
通过次数81,512提交次数118,783
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/zhong-jian-er-cha-shu-lcof
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func buildTree(preorder []int, inorder []int) *TreeNode { |
493. 翻转对[困难]
给定一个数组 nums ,如果 i < j 且 nums[i] > 2*nums[j] 我们就将 (i, j) 称作一个重要翻转对。
你需要返回给定数组中的重要翻转对的数量。
示例 1:
输入: [1,3,2,3,1]
输出: 2
示例 2:
输入: [2,4,3,5,1]
输出: 3
注意:
给定数组的长度不会超过50000。
输入数组中的所有数字都在32位整数的表示范围内。
通过次数16,072提交次数51,612
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/reverse-pairs
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
前言
本题与「327. 区间和的个数」非常相像。
在 327 题中,我们要对前缀和数组的每一个元素 \textit{preSum}[i]preSum[i],找出所有位于 ii 左侧的下标 jj 的数量,要求 jj 满足 \textit{preSum}[j] \in [\textit{preSum}[i]-\textit{upper}, \textit{preSum}[i]-\textit{lower}]preSum[j]∈[preSum[i]−upper,preSum[i]−lower]。而在此题中,我们则要对数组中的每一个元素 \textit{sum}[i]sum[i],找出位于 ii 左侧,且满足 \textit{nums}[j] > 2\cdot \textit{nums}[i]nums[j]>2⋅nums[i] 的下标 jj。
不难发现,二者都是要对数组中的每一个元素,统计「在它左侧,且取值位于某个区间」的元素数量。两个问题唯一的区别仅仅在于取值区间的不同,因此可以用相似的方法解决这两个问题。
在「327 题的题解:区间和的个数」中,我们介绍了归并排序、线段树、树状数组以及平衡搜索树等多种解法。对于本题,我们只给出基于归并排序与树状数组的方法,感兴趣的读者可以参照前面给出的链接,自行完成其他方法的代码。
方法一:归并排序
思路及解法
在归并排序的过程中,假设对于数组 \textit{nums}[l..r]nums[l..r] 而言,我们已经分别求出了子数组 \textit{nums}[l..m]nums[l..m] 与 \textit{nums}[m+1..r]nums[m+1..r] 的翻转对数目,并已将两个子数组分别排好序,则 \textit{nums}[l..r]nums[l..r] 中的翻转对数目,就等于两个子数组的翻转对数目之和,加上左右端点分别位于两个子数组的翻转对数目。
我们可以为两个数组分别维护指针 i,ji,j。对于任意给定的 ii 而言,我们不断地向右移动 jj,直到 \textit{nums}[i] \le 2\cdot \textit{nums}[j]nums[i]≤2⋅nums[j]。此时,意味着以 ii 为左端点的翻转对数量为 j-m-1j−m−1。随后,我们再将 ii 向右移动一个单位,并用相同的方式计算以 ii 为左端点的翻转对数量。不断重复这样的过程,就能够求出所有左右端点分别位于两个子数组的翻转对数目。
代码
C++JavaGolangCJavaScript
func reversePairs(nums []int) int {
n := len(nums)
if n <= 1 {
return 0
}
n1 := append([]int(nil), nums[:n/2]...)
n2 := append([]int(nil), nums[n/2:]...)
cnt := reversePairs(n1) + reversePairs(n2) // 递归完毕后,n1 和 n2 均为有序
// 统计重要翻转对 (i,j) 的数量
// 由于 n1 和 n2 均为有序,可以用两个指针同时遍历
j := 0
for _, v := range n1 {
for j < len(n2) && v > 2*n2[j] {
j++
}
cnt += j
}
// n1 和 n2 归并填入 nums
p1, p2 := 0, 0
for i := range nums {
if p1 < len(n1) && (p2 == len(n2) || n1[p1] <= n2[p2]) {
nums[i] = n1[p1]
p1++
} else {
nums[i] = n2[p2]
p2++
}
}
return cnt}
复杂度分析
时间复杂度:O(N\log N)O(NlogN),其中 NN 为数组的长度。
空间复杂度:O(N)O(N),其中 NN 为数组的长度。
方法二:树状数组
思路及解法
树状数组支持的基本查询为求出 [1, \textit{val}][1,val] 之间的整数数量。因此,对于 \textit{nums}[i]nums[i] 而言,我们首先查询 [1,2\cdot\textit{nums}[i]][1,2⋅nums[i]] 的数量,再求出 [1,\textit{maxValue}][1,maxValue] 的数量(其中 \textit{maxValue}maxValue 为数组中最大元素的二倍)。二者相减,就能够得到以 ii 为右端点的翻转对数量。
由于数组中整数的范围可能很大,故在使用树状数组解法之前,需要利用哈希表将所有可能出现的整数,映射到连续的整数区间内。
代码
C++JavaGolangCJavaScript
type fenwick struct {
tree []int
}
func newFenwickTree(n int) fenwick {
return fenwick{make([]int, n+1)}
}
func (f fenwick) add(i int) {
for ; i < len(f.tree); i += i & -i {
f.tree[i]++
}
}
func (f fenwick) sum(i int) (res int) {
for ; i > 0; i &= i - 1 {
res += f.tree[i]
}
return
}
func reversePairs(nums []int) (cnt int) {
n := len(nums)
if n <= 1 {
return
}
// 离散化所有下面统计时会出现的元素
allNums := make([]int, 0, 2*n)
for _, v := range nums {
allNums = append(allNums, v, 2*v)
}
sort.Ints(allNums)
k := 1
kth := map[int]int{allNums[0]: k}
for i := 1; i < 2*n; i++ {
if allNums[i] != allNums[i-1] {
k++
kth[allNums[i]] = k
}
}
t := newFenwickTree(k)
for i, v := range nums {
// 统计之前插入了多少个比 2*v 大的数
cnt += i - t.sum(kth[2*v])
t.add(kth[v])
}
return}
复杂度分析
时间复杂度:O(N\log N)O(NlogN),其中 NN 为数组的长度。
空间复杂度:O(N)O(N),其中 NN 为数组的长度。
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/reverse-pairs/solution/fan-zhuan-dui-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
5614. 找出最具竞争力的子序列[中等]
给你一个整数数组 nums 和一个正整数 k ,返回长度为 k 且最具 竞争力 的 nums 子序列。
数组的子序列是从数组中删除一些元素(可能不删除元素)得到的序列。
在子序列 a 和子序列 b 第一个不相同的位置上,如果 a 中的数字小于 b 中对应的数字,那么我们称子序列 a 比子序列 b(相同长度下)更具 竞争力 。 例如,[1,3,4] 比 [1,3,5] 更具竞争力,在第一个不相同的位置,也就是最后一个位置上, 4 小于 5 。
示例 1:
输入:nums = [3,5,2,6], k = 2
输出:[2,6]
解释:在所有可能的子序列集合 {[3,5], [3,2], [3,6], [5,2], [5,6], [2,6]} 中,[2,6] 最具竞争力。
示例 2:
输入:nums = [2,4,3,3,5,4,9,6], k = 4
输出:[2,3,3,4]
提示:
1 <= nums.length <= 105
0 <= nums[i] <= 109
1 <= k <= nums.length
通过次数1,122提交次数7,245
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/find-the-most-competitive-subsequence
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
- 超时解法1
1 | func mostCompetitive(nums []int, k int) []int { |
- 超时解法2
1 | func mostCompetitive(nums []int, k int) []int { |
- ac解法
使用栈存储最优1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19func mostCompetitive(nums []int, k int) []int {
if len(nums) <= k {
return nums
}
ans := []int{}
stack := make([]int, len(nums))
top := -1
for i := 0;i < len(nums);i ++{
for top >= 0 && nums[i] < stack[top] && len(nums) - i + top >= k/*剩余的要够K*/ {
top --
}
top ++
stack[top] = nums[i]
}
for i := 0;i < k;i ++{
ans = append(ans, stack[i])
}
return ans
}767. 重构字符串[中等]
给定一个字符串S,检查是否能重新排布其中的字母,使得两相邻的字符不同。
若可行,输出任意可行的结果。若不可行,返回空字符串。
示例 1:
输入: S = “aab”
输出: “aba”
示例 2:
输入: S = “aaab”
输出: “”
注意:
S 只包含小写字母并且长度在[1, 500]区间内。
通过次数24,938提交次数53,783
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/reorganize-string
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
首先统计每个字母的出现次数,然后根据每个字母的出现次数重构字符串。
当 nn 是奇数且出现最多的字母的出现次数是 (n+1)/2(n+1)/2 时,出现次数最多的字母必须全部放置在偶数下标,否则一定会出现相邻的字母相同的情况。其余情况下,每个字母放置在偶数下标或者奇数下标都是可行的。
维护偶数下标 \textit{evenIndex}evenIndex 和奇数下标 \textit{oddIndex}oddIndex,初始值分别为 00 和 11。遍历每个字母,根据每个字母的出现次数判断字母应该放置在偶数下标还是奇数下标。
首先考虑是否可以放置在奇数下标。根据上述分析可知,只要字母的出现次数不超过字符串的长度的一半(即出现次数小于或等于 n/2n/2),就可以放置在奇数下标,只有当字母的出现次数超过字符串的长度的一半时,才必须放置在偶数下标。字母的出现次数超过字符串的长度的一半只可能发生在 nn 是奇数的情况下,且最多只有一个字母的出现次数会超过字符串的长度的一半。
因此通过如下操作在重构的字符串中放置字母。
如果字母的出现次数大于 00 且小于或等于 n/2n/2,且 \textit{oddIndex}oddIndex 没有超出数组下标范围,则将字母放置在 \textit{oddIndex}oddIndex,然后将 \textit{oddIndex}oddIndex 的值加 22。
如果字母的出现次数大于 n/2n/2,或 \textit{oddIndex}oddIndex 超出数组下标范围,则将字母放置在 \textit{evenIndex}evenIndex,然后将 \textit{evenIndex}evenIndex 的值加 22。
如果一个字母出现了多次,则重复上述操作,直到该字母全部放置完毕。
那么上述做法是否可以确保相邻的字母都不相同?考虑以下三种情况。
如果 nn 是奇数且存在一个字母的出现次数为 (n+1)/2(n+1)/2,则该字母全部被放置在偶数下标,其余的 (n-1)/2(n−1)/2 个字母都被放置在奇数下标,因此相邻的字母一定不相同。
如果同一个字母全部被放置在奇数下标或全部被放置在偶数下标,则该字母不可能在相邻的下标出现。
如果同一个字母先被放置在奇数下标直到奇数下标超出数组下标范围,然后被放置在偶数下标,由于该字母的出现次数不会超过 n/2n/2,因此该字母的最小奇数下标与最大偶数下标之差不小于 33,不可能在相邻的下标出现。证明如下:
当 nn 是偶数时,如果该字母的出现次数为 n/2n/2,包括 pp 个奇数下标和 qq 个偶数下标,满足 p+q=n/2p+q=n/2,最小奇数下标是 n-2p+1n−2p+1,最大偶数下标是 2(q-1)2(q−1),最小奇数下标与最大偶数下标之差为:
\begin{aligned} & (n-2p+1)-2(q-1) \ = &\ n-2p+1-2q+2 \ = &\ n-2(p+q)+3 \ = &\ n-2 \times \frac{n}{2}+3 \ = &\ n-n+3 \ = &\ 3 \end{aligned}
=
=
=
=
=
(n−2p+1)−2(q−1)
n−2p+1−2q+2
n−2(p+q)+3
n−2×
2
n
+3
n−n+3
3
当 nn 是奇数时,如果该字母的出现次数为 (n-1)/2(n−1)/2,包括 pp 个奇数下标和 qq 个偶数下标,满足 p+q=(n-1)/2p+q=(n−1)/2,最小奇数下标是 n-2pn−2p,最大偶数下标是 2(q-1)2(q−1),最小奇数下标与最大偶数下标之差为:
\begin{aligned} & (n-2p)-2(q-1) \ = &\ n-2p-2q+2 \ = &\ n-2(p+q)+2 \ = &\ n-2 \times \frac{n-1}{2}+2 \ = &\ n-(n-1)+2 \ = &\ 3 \end{aligned}
=
=
=
=
=
(n−2p)−2(q−1)
n−2p−2q+2
n−2(p+q)+2
n−2×
2
n−1
+2
n−(n−1)+2
3
因此,在重构字符串可行的情况下,基于计数的贪心算法可以确保相邻的字母都不相同,得到正确答案。
1 |
|
复杂度分析
时间复杂度:O(n+|\Sigma|)O(n+∣Σ∣),其中 nn 是字符串的长度,\SigmaΣ 是字符集,在本题中字符集为所有小写字母,|\Sigma|=26∣Σ∣=26。
遍历字符串并统计每个字母的出现次数,时间复杂度是 O(n)O(n)。
重构字符串需要进行 nn 次放置字母的操作,并遍历每个字母得到出现次数,时间复杂度是 O(n+|\Sigma|)O(n+∣Σ∣)。
总时间复杂度是 O(n+|\Sigma|)O(n+∣Σ∣)。
空间复杂度:O(|\Sigma|)O(∣Σ∣),其中 nn 是字符串的长度,\SigmaΣ 是字符集,在本题中字符集为所有小写字母,|\Sigma|=26∣Σ∣=26。这里不计算存储最终答案字符串需要的空间(以及由于语言特性,在构造字符串时需要的额外缓存空间),空间复杂度主要取决于统计每个字母出现次数的数组和优先队列。空间复杂度主要取决于统计每个字母出现次数的数组。
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/reorganize-string/solution/zhong-gou-zi-fu-chuan-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
23. 合并K个升序链表[困难]
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]]
输出:[1,1,2,3,4,4,5,6]
解释:链表数组如下:
[
1->4->5,
1->3->4,
2->6
]
将它们合并到一个有序链表中得到。
1->1->2->3->4->4->5->6
示例 2:
输入:lists = []
输出:[]
示例 3:
输入:lists = [[]]
输出:[]
提示:
k == lists.length
0 <= k <= 10^4
0 <= lists[i].length <= 500
-10^4 <= lists[i][j] <= 10^4
lists[i] 按 升序 排列
lists[i].length 的总和不超过 10^4
通过次数191,226提交次数356,108
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/merge-k-sorted-lists
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func mergeKLists(lists []*ListNode) *ListNode { |
4. 寻找两个正序数组的中位数[困难]
给定两个大小为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的中位数。
进阶:你能设计一个时间复杂度为 O(log (m+n)) 的算法解决此问题吗?
示例 1:
输入:nums1 = [1,3], nums2 = [2]
输出:2.00000
解释:合并数组 = [1,2,3] ,中位数 2
示例 2:
输入:nums1 = [1,2], nums2 = [3,4]
输出:2.50000
解释:合并数组 = [1,2,3,4] ,中位数 (2 + 3) / 2 = 2.5
示例 3:
输入:nums1 = [0,0], nums2 = [0,0]
输出:0.00000
示例 4:
输入:nums1 = [], nums2 = [1]
输出:1.00000
示例 5:
输入:nums1 = [2], nums2 = []
输出:2.00000
提示:
nums1.length == m
nums2.length == n
0 <= m <= 1000
0 <= n <= 1000
1 <= m + n <= 2000
-106 <= nums1[i], nums2[i] <= 106
通过次数296,624提交次数756,816
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/median-of-two-sorted-arrays
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func findMedianSortedArrays(nums1 []int, nums2 []int) float64 { |
34. 在排序数组中查找元素的第一个和最后一个位置[中等]
给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
进阶:
你可以设计并实现时间复杂度为 O(log n) 的算法解决此问题吗?
示例 1:
输入:nums = [5,7,7,8,8,10], target = 8
输出:[3,4]
示例 2:
输入:nums = [5,7,7,8,8,10], target = 6
输出:[-1,-1]
示例 3:
输入:nums = [], target = 0
输出:[-1,-1]
提示:
0 <= nums.length <= 105
-109 <= nums[i] <= 109
nums 是一个非递减数组
-109 <= target <= 109
通过次数175,183提交次数420,917
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/find-first-and-last-position-of-element-in-sorted-array
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func searchRange(nums []int, target int) []int { |
面试题 02.05. 链表求和[中等]
给定两个用链表表示的整数,每个节点包含一个数位。
这些数位是反向存放的,也就是个位排在链表首部。
编写函数对这两个整数求和,并用链表形式返回结果。
示例:
输入:(7 -> 1 -> 6) + (5 -> 9 -> 2),即617 + 295
输出:2 -> 1 -> 9,即912
进阶:思考一下,假设这些数位是正向存放的,又该如何解决呢?
示例:
输入:(6 -> 1 -> 7) + (2 -> 9 -> 5),即617 + 295
输出:9 -> 1 -> 2,即912
通过次数17,839提交次数38,870
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/sum-lists-lcci
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func addTwoNumbers(l1 *ListNode, l2 *ListNode) *ListNode { |
剑指 Offer 59 - II. 队列的最大值[中等]
请定义一个队列并实现函数 max_value 得到队列里的最大值,要求函数max_value、push_back 和 pop_front 的均摊时间复杂度都是O(1)。
若队列为空,pop_front 和 max_value 需要返回 -1
示例 1:
输入:
[“MaxQueue”,”push_back”,”push_back”,”max_value”,”pop_front”,”max_value”]
[[],[1],[2],[],[],[]]
输出: [null,null,null,2,1,2]
示例 2:
输入:
[“MaxQueue”,”pop_front”,”max_value”]
[[],[],[]]
输出: [null,-1,-1]
限制:
1 <= push_back,pop_front,max_value的总操作数 <= 10000
1 <= value <= 10^5
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/dui-lie-de-zui-da-zhi-lcof
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
而外维持一个最大值的队列,这个最大值的队列对头肯定是当前最大的值。如果有新的进来,更新最大值队列。如何更新,将小于这个值得数据抛弃。里面肯定是单调递减的。
1 | type MaxQueue struct { |
25. K 个一组翻转链表[困难]
给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表。
k 是一个正整数,它的值小于或等于链表的长度。
如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
示例:
给你这个链表:1->2->3->4->5
当 k = 2 时,应当返回: 2->1->4->3->5
当 k = 3 时,应当返回: 3->2->1->4->5
说明:
你的算法只能使用常数的额外空间。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
通过次数117,933提交次数185,212
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/reverse-nodes-in-k-group
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func reverse(head *ListNode) *ListNode{ |
1669. 合并两个链表[中等]
给你两个链表 list1 和 list2 ,它们包含的元素分别为 n 个和 m 个。
请你将 list1 中第 a 个节点到第 b 个节点删除,并将list2 接在被删除节点的位置。
下图中蓝色边和节点展示了操作后的结果:
请你返回结果链表的头指针。
示例 1:
输入:list1 = [0,1,2,3,4,5], a = 3, b = 4, list2 = [1000000,1000001,1000002]
输出:[0,1,2,1000000,1000001,1000002,5]
解释:我们删除 list1 中第三和第四个节点,并将 list2 接在该位置。上图中蓝色的边和节点为答案链表。
示例 2:
输入:list1 = [0,1,2,3,4,5,6], a = 2, b = 5, list2 = [1000000,1000001,1000002,1000003,1000004]
输出:[0,1,1000000,1000001,1000002,1000003,1000004,6]
解释:上图中蓝色的边和节点为答案链表。
提示:
3 <= list1.length <= 104
1 <= a <= b < list1.length - 1
1 <= list2.length <= 104
通过次数2,046提交次数2,515
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/merge-in-between-linked-lists
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func mergeInBetween(list1 *ListNode, a int, b int, list2 *ListNode) *ListNode { |
面试题 17.09. 第 k 个数[中等]
有些数的素因子只有 3,5,7,请设计一个算法找出第 k 个数。注意,不是必须有这些素因子,而是必须不包含其他的素因子。例如,前几个数按顺序应该是 1,3,5,7,9,15,21。
示例 1:
输入: k = 5
输出: 9
通过次数7,350提交次数13,530
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/get-kth-magic-number-lcci
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func min(x,y int) int { |
328. 奇偶链表[中等]
给定一个单链表,把所有的奇数节点和偶数节点分别排在一起。请注意,这里的奇数节点和偶数节点指的是节点编号的奇偶性,而不是节点的值的奇偶性。
请尝试使用原地算法完成。你的算法的空间复杂度应为 O(1),时间复杂度应为 O(nodes),nodes 为节点总数。
示例 1:
输入: 1->2->3->4->5->NULL
输出: 1->3->5->2->4->NULL
示例 2:
输入: 2->1->3->5->6->4->7->NULL
输出: 2->3->6->7->1->5->4->NULL
说明:
应当保持奇数节点和偶数节点的相对顺序。
链表的第一个节点视为奇数节点,第二个节点视为偶数节点,以此类推。
通过次数87,539提交次数133,658
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/odd-even-linked-list
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func oddEvenList(head *ListNode) *ListNode { |
659. 分割数组为连续子序列[中等]
给你一个按升序排序的整数数组 num(可能包含重复数字),请你将它们分割成一个或多个子序列,其中每个子序列都由连续整数组成且长度至少为 3 。
如果可以完成上述分割,则返回 true ;否则,返回 false 。
示例 1:
输入: [1,2,3,3,4,5]
输出: True
解释:
你可以分割出这样两个连续子序列 :
1, 2, 3
3, 4, 5
示例 2:
输入: [1,2,3,3,4,4,5,5]
输出: True
解释:
你可以分割出这样两个连续子序列 :
1, 2, 3, 4, 5
3, 4, 5
示例 3:
输入: [1,2,3,4,4,5]
输出: False
提示:
输入的数组长度范围为 [1, 10000]
通过次数17,783提交次数34,004
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/split-array-into-consecutive-subsequences
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func isPossible(nums []int) bool { |
LCP 06. 拿硬币[简单]
桌上有 n 堆力扣币,每堆的数量保存在数组 coins 中。我们每次可以选择任意一堆,拿走其中的一枚或者两枚,求拿完所有力扣币的最少次数。
示例 1:
输入:[4,2,1]
输出:4
解释:第一堆力扣币最少需要拿 2 次,第二堆最少需要拿 1 次,第三堆最少需要拿 1 次,总共 4 次即可拿完。
示例 2:
输入:[2,3,10]
输出:8
限制:
1 <= n <= 4
1 <= coins[i] <= 10
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/na-ying-bi
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func minCount(coins []int) int { |
621. 任务调度器[中等]
给你一个用字符数组 tasks 表示的 CPU 需要执行的任务列表。其中每个字母表示一种不同种类的任务。任务可以以任意顺序执行,并且每个任务都可以在 1 个单位时间内执行完。在任何一个单位时间,CPU 可以完成一个任务,或者处于待命状态。
然而,两个 相同种类 的任务之间必须有长度为整数 n 的冷却时间,因此至少有连续 n 个单位时间内 CPU 在执行不同的任务,或者在待命状态。
你需要计算完成所有任务所需要的 最短时间 。
示例 1:
输入:tasks = [“A”,”A”,”A”,”B”,”B”,”B”], n = 2
输出:8
解释:A -> B -> (待命) -> A -> B -> (待命) -> A -> B
在本示例中,两个相同类型任务之间必须间隔长度为 n = 2 的冷却时间,而执行一个任务只需要一个单位时间,所以中间出现了(待命)状态。
示例 2:
输入:tasks = [“A”,”A”,”A”,”B”,”B”,”B”], n = 0
输出:6
解释:在这种情况下,任何大小为 6 的排列都可以满足要求,因为 n = 0
[“A”,”A”,”A”,”B”,”B”,”B”]
[“A”,”B”,”A”,”B”,”A”,”B”]
[“B”,”B”,”B”,”A”,”A”,”A”]
…
诸如此类
示例 3:
输入:tasks = [“A”,”A”,”A”,”A”,”A”,”A”,”B”,”C”,”D”,”E”,”F”,”G”], n = 2
输出:16
解释:一种可能的解决方案是:
A -> B -> C -> A -> D -> E -> A -> F -> G -> A -> (待命) -> (待命) -> A -> (待命) -> (待命) -> A
提示:
1 <= task.length <= 104
tasks[i] 是大写英文字母
n 的取值范围为 [0, 100]
通过次数46,923提交次数86,906
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/task-scheduler
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
方法一:模拟
思路与算法
一种容易想到的方法是,我们按照时间顺序,依次给每一个时间单位分配任务。
那么如果当前有多种任务不在冷却中,那么我们应该如何挑选执行的任务呢?直觉上,我们应当选择剩余执行次数最多的那个任务,将每种任务的剩余执行次数尽可能平均,使得 CPU 处于待命状态的时间尽可能少。当然这也是可以证明的,详细证明见下一个小标题。
因此我们可以用二元组 (\textit{nextValid}_i, \textit{rest}_i)(nextValid
i
,rest
i
) 表示第 ii 个任务,其中 \textit{nextValid}_inextValid
i
表示其因冷却限制,最早可以执行的时间;\textit{rest}_irest
i
表示其剩余执行次数。初始时,所有的 \textit{nextValid}_inextValid
i
均为 11,而 \textit{rest}_irest
i
即为任务 ii 在数组 \textit{tasks}tasks 中出现的次数。
我们用 \textit{time}time 记录当前的时间。根据我们的策略,我们需要选择不在冷却中并且剩余执行次数最多的那个任务,也就是说,我们需要找到满足 \textit{nextValid}_i \leq \textit{time}nextValid
i
≤time 的并且 \textit{rest}_irest
i
最大的索引 ii。因此我们只需要遍历所有的二元组,即可找到 ii。在这之后,我们将 (\textit{nextValid}_i, \textit{rest}_i)(nextValid
i
,rest
i
) 更新为 (\textit{time}+n+1, \textit{rest}_i-1)(time+n+1,rest
i
−1),记录任务 ii 下一次冷却结束的时间以及剩余执行次数。如果更新后的 \textit{rest}_i=0rest
i
=0,那么任务 ii 全部做完,我们在遍历二元组时也就可以忽略它了。
而对于 \textit{time}time 的更新,我们可以选择将其不断增加 11,模拟每一个时间片。但这会导致我们在 CPU 处于待命状态时,对二元组进行不必要的遍历。为了减少时间复杂度,我们可以在每一次遍历之前,将 \textit{time}time 更新为所有 \textit{nextValid}_inextValid
i
中的最小值,直接「跳过」待命状态,保证每一次对二元组的遍历都是有效的。需要注意的是,只有当这个最小值大于 \textit{time}time 时,才需要这样快速更新。
证明
对于某个时间点 tt,设任务 aa 和 bb 均不在冷却中,并且它们分别剩余 pp 和 qq 次。不失一般性,假设 p>qp>q,那么我们应当在此时选择任务 aa,但我们选择了任务 bb。我们需要证明,存在一种交换方法,使得将此时的任务 bb「变成」任务 aa 后,总时间不会增加。
为了叙述方便,设 a_1, a_2, \cdots, a_pa
1
,a
2
,⋯,a
p
为选择任务 aa 的时间点,b_1, b_2, \cdots, b_qb
1
,b
2
,⋯,b
q
为选择任务 bb 的时间点,根据假设有
a_1 > b_1 = t
a
1
b
1
=t
以及对于任意相邻的两项 a_i, a_{i+1}a
i
,a
i+1
或者 b_j, b_{j+1}b
j
,b
j+1
,均有
a_{i+1} - a_i > n
a
i+1
−a
i
n
以及
b_{j+1} - b_j > n
b
j+1
−b
j
n
接下来我们分情况讨论:
如果 \exists k’ \in [2, q]∃k
′
∈[2,q] 使得 a_{k’} < b_{k’}a
k
′
<b
k
′
,那么我们找出其中最小的那个 k’k
′
记为 kk。此时我们有
\begin{cases} a_1 > b_1 \ a_2 > b_2 \ \cdots \ a_{k-1} > b_{k-1} \ a_k < b_k \end{cases}
⎩
⎪
⎪
⎪
⎪
⎪
⎪
⎪
⎨
⎪
⎪
⎪
⎪
⎪
⎪
⎪
⎧
a
1
b
1
a
2
b
2
⋯
a
k−1
b
k−1
a
k
<b
k
那么我们可以构造序列:
b_1, b_2, \cdots, b_{k-1}, a_k, a_{k+1}, \cdots, a_pb
1
,b
2
,⋯,b
k−1
,a
k
,a
k+1
,⋯,a
p
作为交换后选择任务 aa 的时间点;
a_1, a_2, \cdots, a_{k-1}, b_k, b_{k+1}, \cdots, b_qa
1
,a
2
,⋯,a
k−1
,b
k
,b
k+1
,⋯,b
q
作为交换后选择任务 bb 的时间点。
对于交换后任务 aa 的序列,其一共有 pp 项,并且有
a_k - b_{k-1} > a_k - a_{k-1} > n
a
k
−b
k−1
a
k
−a
k−1
n
因此其满足任意相邻两项之差大于 nn,不会违反冷却时间的规则。
同理对于对于交换后任务 bb 的序列,其一共有 qq 项,并且有
b_k - a_{k-1} > a_k - a_{k-1} > n
b
k
−a
k−1
a
k
−a
k−1
n
同样不会违反冷却时间的规则。
如果 \forall k’ \in [2, q]∀k
′
∈[2,q] 均有 a_{k’} > b_{k’}a
k
′
b
k
′
,那么我们只要构造序列:
b_1, b_2, \cdots, b_kb
1
,b
2
,⋯,b
k
作为交换后选择任务 aa 的时间点;
a_1, a_2, \cdots, a_k, b_{k+1}, \cdots, b_na
1
,a
2
,⋯,a
k
,b
k+1
,⋯,b
n
作为交换后选择任务 bb 的时间点。
由于 b_{k+1} - a_k > b_{k+1} - b_k > nb
k+1
−a
k
b
k+1
−b
k
n,因此不会违反冷却时间的规则。
无论哪一种情况,我们都将 b_1=tb
1
=t 变成了选择任务 aa 的时间点,并且由于我们只在任务 aa 和 bb 的内部进行交换,因此交换后总时间一定不会增加。这样就证明了一定存在一种总时间最少的方法,是通过不断地选择不在冷却中并且剩余执行次数最多的那个任务得到的。
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/task-scheduler/solution/ren-wu-diao-du-qi-by-leetcode-solution-ur9w/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1 | func leastInterval(tasks []byte, n int) (minTime int) { |
剑指 Offer 53 - I. 在排序数组中查找数字 I[简单]
统计一个数字在排序数组中出现的次数。
示例 1:
输入: nums = [5,7,7,8,8,10], target = 8
输出: 2
示例 2:
输入: nums = [5,7,7,8,8,10], target = 6
输出: 0
限制:
0 <= 数组长度 <= 50000
注意:本题与主站 34 题相同(仅返回值不同):https://leetcode-cn.com/problems/find-first-and-last-position-of-element-in-sorted-array/
通过次数62,297提交次数117,791
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/zai-pai-xu-shu-zu-zhong-cha-zhao-shu-zi-lcof
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func search(nums []int, target int) int { |
剑指 Offer 17. 打印从1到最大的n位数[简单]
输入数字 n,按顺序打印出从 1 到最大的 n 位十进制数。比如输入 3,则打印出 1、2、3 一直到最大的 3 位数 999。
示例 1:
输入: n = 1
输出: [1,2,3,4,5,6,7,8,9]
说明:
用返回一个整数列表来代替打印
n 为正整数
通过次数70,318提交次数89,741
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/da-yin-cong-1dao-zui-da-de-nwei-shu-lcof
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func printNumbers(n int) []int { |
861. 翻转矩阵后的得分[中等]
有一个二维矩阵 A 其中每个元素的值为 0 或 1 。
移动是指选择任一行或列,并转换该行或列中的每一个值:将所有 0 都更改为 1,将所有 1 都更改为 0。
在做出任意次数的移动后,将该矩阵的每一行都按照二进制数来解释,矩阵的得分就是这些数字的总和。
返回尽可能高的分数。
示例:
输入:[[0,0,1,1],[1,0,1,0],[1,1,0,0]]
输出:39
解释:
转换为 [[1,1,1,1],[1,0,0,1],[1,1,1,1]]
0b1111 + 0b1001 + 0b1111 = 15 + 9 + 15 = 39
提示:
1 <= A.length <= 20
1 <= A[0].length <= 20
A[i][j] 是 0 或 1
通过次数21,908提交次数27,082
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/score-after-flipping-matrix
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
方法一:贪心
根据题意,能够知道一个重要的事实:给定一个翻转方案,则它们之间任意交换顺序后,得到的结果保持不变。因此,我们总可以先考虑所有的行翻转,再考虑所有的列翻转。
不难发现一点:为了得到最高的分数,矩阵的每一行的最左边的数都必须为 11。为了做到这一点,我们可以翻转那些最左边的数不为 11 的那些行,而其他的行则保持不动。
当将每一行的最左边的数都变为 11 之后,就只能进行列翻转了。为了使得总得分最大,我们要让每个列中 11 的数目尽可能多。因此,我们扫描除了最左边的列以外的每一列,如果该列 00 的数目多于 11 的数目,就翻转该列,其他的列则保持不变。
实际编写代码时,我们无需修改原矩阵,而是可以计算每一列对总分数的「贡献」,从而直接计算出最高的分数。假设矩阵共有 mm 行 nn 列,计算方法如下:
对于最左边的列而言,由于最优情况下,它们的取值都为 11,因此每个元素对分数的贡献都为 2^{n-1}2
n−1
,总贡献为 m \times 2^{n-1}m×2
n−1
。
对于第 jj 列(j>0j>0,此处规定最左边的列是第 00 列)而言,我们统计这一列 0,10,1 的数量,令其中的最大值为 kk,则 kk 是列翻转后的 11 的数量,该列的总贡献为 k \times 2^{n-j-1}k×2
n−j−1
。需要注意的是,在统计 0,10,1 的数量的时候,要考虑最初进行的行反转。
1 | func matrixScore(a [][]int) int { |
复杂度分析
时间复杂度:O(mn)O(mn),其中 mm 为矩阵行数,nn 为矩阵列数。
空间复杂度:O(1)O(1)。
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/score-after-flipping-matrix/solution/fan-zhuan-ju-zhen-hou-de-de-fen-by-leetc-cxma/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1680. 连接连续二进制数字[中等]
给你一个整数 n ,请你将 1 到 n 的二进制表示连接起来,并返回连接结果对应的 十进制 数字对 109 + 7 取余的结果。
示例 1:
输入:n = 1
输出:1
解释:二进制的 “1” 对应着十进制的 1 。
示例 2:
输入:n = 3
输出:27
解释:二进制下,1,2 和 3 分别对应 “1” ,”10” 和 “11” 。
将它们依次连接,我们得到 “11011” ,对应着十进制的 27 。
示例 3:
输入:n = 12
输出:505379714
解释:连接结果为 “1101110010111011110001001101010111100” 。
对应的十进制数字为 118505380540 。
对 109 + 7 取余后,结果为 505379714 。
提示:
1 <= n <= 105
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/concatenation-of-consecutive-binary-numbers
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 |
|
面试题 17.10. 主要元素[简单]
数组中占比超过一半的元素称之为主要元素。给定一个整数数组,找到它的主要元素。若没有,返回-1。
示例 1:
输入:[1,2,5,9,5,9,5,5,5]
输出:5
示例 2:
输入:[3,2]
输出:-1
示例 3:
输入:[2,2,1,1,1,2,2]
输出:2
说明:
你有办法在时间复杂度为 O(N),空间复杂度为 O(1) 内完成吗?
通过次数22,420提交次数38,902
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/find-majority-element-lcci
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func majorityElement(nums []int) int { |
860. 柠檬水找零[简单]
在柠檬水摊上,每一杯柠檬水的售价为 5 美元。
顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。
每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。
注意,一开始你手头没有任何零钱。
如果你能给每位顾客正确找零,返回 true ,否则返回 false 。
示例 1:
输入:[5,5,5,10,20]
输出:true
解释:
前 3 位顾客那里,我们按顺序收取 3 张 5 美元的钞票。
第 4 位顾客那里,我们收取一张 10 美元的钞票,并返还 5 美元。
第 5 位顾客那里,我们找还一张 10 美元的钞票和一张 5 美元的钞票。
由于所有客户都得到了正确的找零,所以我们输出 true。
示例 2:
输入:[5,5,10]
输出:true
示例 3:
输入:[10,10]
输出:false
示例 4:
输入:[5,5,10,10,20]
输出:false
解释:
前 2 位顾客那里,我们按顺序收取 2 张 5 美元的钞票。
对于接下来的 2 位顾客,我们收取一张 10 美元的钞票,然后返还 5 美元。
对于最后一位顾客,我们无法退回 15 美元,因为我们现在只有两张 10 美元的钞票。
由于不是每位顾客都得到了正确的找零,所以答案是 false。
提示:
0 <= bills.length <= 10000
bills[i] 不是 5 就是 10 或是 20
通过次数35,803提交次数63,683
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/lemonade-change
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
贪心,先付大的,再付小的。
1 |
|
455. 分发饼干[简单]
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
示例 1:
输入: g = [1,2,3], s = [1,1]
输出: 1
解释:
你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。
虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩子满足。
所以你应该输出1。
示例 2:
输入: g = [1,2], s = [1,2,3]
输出: 2
解释:
你有两个孩子和三块小饼干,2个孩子的胃口值分别是1,2。
你拥有的饼干数量和尺寸都足以让所有孩子满足。
所以你应该输出2.
提示:
1 <= g.length <= 3 * 104
0 <= s.length <= 3 * 104
1 <= g[i], s[j] <= 231 - 1
通过次数65,009提交次数115,716
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/assign-cookies
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func findContentChildren(g []int, s []int) int { |
842. 将数组拆分成斐波那契序列[中等]
给定一个数字字符串 S,比如 S = “123456579”,我们可以将它分成斐波那契式的序列 [123, 456, 579]。
形式上,斐波那契式序列是一个非负整数列表 F,且满足:
0 <= F[i] <= 2^31 - 1,(也就是说,每个整数都符合 32 位有符号整数类型);
F.length >= 3;
对于所有的0 <= i < F.length - 2,都有 F[i] + F[i+1] = F[i+2] 成立。
另外,请注意,将字符串拆分成小块时,每个块的数字一定不要以零开头,除非这个块是数字 0 本身。
返回从 S 拆分出来的任意一组斐波那契式的序列块,如果不能拆分则返回 []。
示例 1:
输入:”123456579”
输出:[123,456,579]
示例 2:
输入: “11235813”
输出: [1,1,2,3,5,8,13]
示例 3:
输入: “112358130”
输出: []
解释: 这项任务无法完成。
示例 4:
输入:”0123”
输出:[]
解释:每个块的数字不能以零开头,因此 “01”,”2”,”3” 不是有效答案。
示例 5:
输入: “1101111”
输出: [110, 1, 111]
解释: 输出 [11,0,11,11] 也同样被接受。
提示:
1 <= S.length <= 200
字符串 S 中只含有数字。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/split-array-into-fibonacci-sequence
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func splitIntoFibonacci(s string) (F []int) { |
213. 打家劫舍 II[中等]
你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都 围成一圈 ,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警 。
给定一个代表每个房屋存放金额的非负整数数组,计算你 在不触动警报装置的情况下 ,能够偷窃到的最高金额。
示例 1:
输入:nums = [2,3,2]
输出:3
解释:你不能先偷窃 1 号房屋(金额 = 2),然后偷窃 3 号房屋(金额 = 2), 因为他们是相邻的。
示例 2:
输入:nums = [1,2,3,1]
输出:4
解释:你可以先偷窃 1 号房屋(金额 = 1),然后偷窃 3 号房屋(金额 = 3)。
偷窃到的最高金额 = 1 + 3 = 4 。
示例 3:
输入:nums = [0]
输出:0
提示:
1 <= nums.length <= 100
0 <= nums[i] <= 1000
通过次数66,513提交次数165,803
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/house-robber-ii
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func rob(nums []int) int { |
动态规划–路径问题
62. 不同路径[中等]
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
示例 1: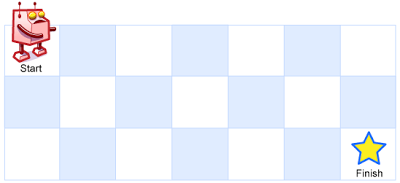
输入:m = 3, n = 7
输出:28
示例 2:
输入:m = 3, n = 2
输出:3
解释:
从左上角开始,总共有 3 条路径可以到达右下角。
- 向右 -> 向右 -> 向下
- 向右 -> 向下 -> 向右
- 向下 -> 向右 -> 向右
示例 3:
输入:m = 7, n = 3
输出:28
示例 4:
输入:m = 3, n = 3
输出:6
提示:
1 <= m, n <= 100
题目数据保证答案小于等于 2 * 109
通过次数187,109提交次数294,386
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/unique-paths
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路
动态规划,处于i,j的节点路径个数等于(i -1,j) (i,j -1)两个点之和。当前的节点受前面数据影响,但不会反过来影响前面的节点。这既是终点又是起点。注意边缘只受左或上节点影响。
1 | func uniquePaths(m int, n int) int { |
63. 不同路径 II[中等]
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
网格中的障碍物和空位置分别用 1 和 0 来表示。
示例 1:
输入:obstacleGrid = [[0,0,0],[0,1,0],[0,0,0]]
输出:2
解释:
3x3 网格的正中间有一个障碍物。
从左上角到右下角一共有 2 条不同的路径:
- 向右 -> 向右 -> 向下 -> 向下
- 向下 -> 向下 -> 向右 -> 向右
示例 2:

输入:obstacleGrid = [[0,1],[0,0]]
输出:1
提示:
m == obstacleGrid.length
n == obstacleGrid[i].length
1 <= m, n <= 100
obstacleGrid[i][j] 为 0 或 1
通过次数112,978提交次数303,865
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/unique-paths-ii
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
和上一题一样,只是判断条件变更一下。
1 | func uniquePathsWithObstacles(obstacleGrid [][]int) int { |
64. 最小路径和[中等]
给定一个包含非负整数的 m x n 网格 grid ,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
说明:每次只能向下或者向右移动一步。
示例 1:
输入:grid = [[1,3,1],[1,5,1],[4,2,1]]
输出:7
解释:因为路径 1→3→1→1→1 的总和最小。
示例 2:
输入:grid = [[1,2,3],[4,5,6]]
输出:12
提示:
m == grid.length
n == grid[i].length
1 <= m, n <= 200
0 <= grid[i][j] <= 100
通过次数164,703提交次数242,840
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/minimum-path-sum
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
和前面两题一致,只不过现在存储的是最小路径了
1 |
|
120. 三角形最小路径和[中等]
给定一个三角形,找出自顶向下的最小路径和。每一步只能移动到下一行中相邻的结点上。
相邻的结点 在这里指的是 下标 与 上一层结点下标 相同或者等于 上一层结点下标 + 1 的两个结点。
例如,给定三角形:
[
[2],
[3,4],
[6,5,7],
[4,1,8,3]
]
自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11)。
说明:
如果你可以只使用 O(n) 的额外空间(n 为三角形的总行数)来解决这个问题,那么你的算法会很加分。
通过次数120,150提交次数179,666
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/triangle
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
思路和上面的那一题一样,只不过需要使用O(n)的空间,
1 |
|
91. 解码方法[中等]
一条包含字母 A-Z 的消息通过以下方式进行了编码:
‘A’ -> 1
‘B’ -> 2
…
‘Z’ -> 26
给定一个只包含数字的非空字符串,请计算解码方法的总数。
题目数据保证答案肯定是一个 32 位的整数。
示例 1:
输入:s = “12”
输出:2
解释:它可以解码为 “AB”(1 2)或者 “L”(12)。
示例 2:
输入:s = “226”
输出:3
解释:它可以解码为 “BZ” (2 26), “VF” (22 6), 或者 “BBF” (2 2 6) 。
示例 3:
输入:s = “0”
输出:0
示例 4:
输入:s = “1”
输出:1
示例 5:
输入:s = “2”
输出:1
提示:
1 <= s.length <= 100
s 只包含数字,并且可能包含前导零。
通过次数77,303提交次数309,169
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/decode-ways
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func numDecodings(s string) int { |
649. Dota2 参议院[中等]
Dota2 的世界里有两个阵营:Radiant(天辉)和 Dire(夜魇)
Dota2 参议院由来自两派的参议员组成。现在参议院希望对一个 Dota2 游戏里的改变作出决定。他们以一个基于轮为过程的投票进行。在每一轮中,每一位参议员都可以行使两项权利中的一项:
禁止一名参议员的权利:
参议员可以让另一位参议员在这一轮和随后的几轮中丧失所有的权利。
宣布胜利:
如果参议员发现有权利投票的参议员都是同一个阵营的,他可以宣布胜利并决定在游戏中的有关变化。
给定一个字符串代表每个参议员的阵营。字母 “R” 和 “D” 分别代表了 Radiant(天辉)和 Dire(夜魇)。然后,如果有 n 个参议员,给定字符串的大小将是 n。
以轮为基础的过程从给定顺序的第一个参议员开始到最后一个参议员结束。这一过程将持续到投票结束。所有失去权利的参议员将在过程中被跳过。
假设每一位参议员都足够聪明,会为自己的政党做出最好的策略,你需要预测哪一方最终会宣布胜利并在 Dota2 游戏中决定改变。输出应该是 Radiant 或 Dire。
示例 1:
输入:”RD”
输出:”Radiant”
解释:第一个参议员来自 Radiant 阵营并且他可以使用第一项权利让第二个参议员失去权力,因此第二个参议员将被跳过因为他没有任何权利。然后在第二轮的时候,第一个参议员可以宣布胜利,因为他是唯一一个有投票权的人
示例 2:
输入:”RDD”
输出:”Dire”
解释:
第一轮中,第一个来自 Radiant 阵营的参议员可以使用第一项权利禁止第二个参议员的权利
第二个来自 Dire 阵营的参议员会被跳过因为他的权利被禁止
第三个来自 Dire 阵营的参议员可以使用他的第一项权利禁止第一个参议员的权利
因此在第二轮只剩下第三个参议员拥有投票的权利,于是他可以宣布胜利
提示:
给定字符串的长度在 [1, 10,000] 之间.
通过次数20,226提交次数43,548
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/dota2-senate
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
方法一:「循环」队列
思路与算法
我们以天辉方的议员为例。当一名天辉方的议员行使权利时:
如果目前所有的议员都为天辉方,那么该议员可以直接宣布天辉方取得胜利;
如果目前仍然有夜魇方的议员,那么这名天辉方的议员只能行使「禁止一名参议员的权利」这一项权利。显然,该议员不会令一名同为天辉方的议员丧失权利,所以他一定会挑选一名夜魇方的议员。那么应该挑选哪一名议员呢?容易想到的是,应该贪心地挑选按照投票顺序的下一名夜魇方的议员。这也是很容易形象化地证明的:既然只能挑选一名夜魇方的议员,那么就应该挑最早可以进行投票的那一名议员;如果挑选了其它较晚投票的议员,那么等到最早可以进行投票的那一名议员行使权利时,一名天辉方议员就会丧失权利,这样就得不偿失了。
由于我们总要挑选投票顺序最早的议员,因此我们可以使用两个队列 \textit{radiant}radiant 和 \textit{dire}dire 分别按照投票顺序存储天辉方和夜魇方每一名议员的投票时间。随后我们就可以开始模拟整个投票的过程:
如果此时 \textit{radiant}radiant 或者 \textit{dire}dire 为空,那么就可以宣布另一方获得胜利;
如果均不为空,那么比较这两个队列的首元素,就可以确定当前行使权利的是哪一名议员。如果 \textit{radiant}radiant 的首元素较小,那说明轮到天辉方的议员行使权利,其会挑选 \textit{dire}dire 的首元素对应的那一名议员。因此,我们会将 \textit{dire}dire 的首元素永久地弹出,并将 \textit{radiant}radiant 的首元素弹出,增加 nn 之后再重新放回队列,这里 nn 是给定的字符串 \textit{senate}senate 的长度,即表示该议员会参与下一轮的投票。
为什么这里是固定地增加 nn,而不是增加与当前剩余议员数量相关的一个数?读者可以思考一下这里的正确性。
同理,如果 \textit{dire}dire 的首元素较小,那么会永久弹出 \textit{radiant}radiant 的首元素,剩余的处理方法也是类似的。
这样一来,我们就模拟了整个投票的过程,也就可以得到最终的答案了。
代码
1 | func predictPartyVictory(senate string) string { |
复杂度分析
时间复杂度:O(n)O(n),其中 nn 是字符串 \textit{senate}senate 的长度。在模拟整个投票过程的每一步,我们进行的操作的时间复杂度均为 O(1)O(1),并且会弹出一名天辉方或夜魇方的议员。由于议员的数量为 nn,因此模拟的步数不会超过 nn,时间复杂度即为 O(n)O(n)。
空间复杂度:O(n)O(n),即为两个队列需要使用的空间。
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/dota2-senate/solution/dota2-can-yi-yuan-by-leetcode-solution-jb7l/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1518. 换酒问题[简单]
小区便利店正在促销,用 numExchange 个空酒瓶可以兑换一瓶新酒。你购入了 numBottles 瓶酒。
如果喝掉了酒瓶中的酒,那么酒瓶就会变成空的。
请你计算 最多 能喝到多少瓶酒。
示例 1:
输入:numBottles = 9, numExchange = 3
输出:13
解释:你可以用 3 个空酒瓶兑换 1 瓶酒。
所以最多能喝到 9 + 3 + 1 = 13 瓶酒。
示例 2:
输入:numBottles = 15, numExchange = 4
输出:19
解释:你可以用 4 个空酒瓶兑换 1 瓶酒。
所以最多能喝到 15 + 3 + 1 = 19 瓶酒。
示例 3:
输入:numBottles = 5, numExchange = 5
输出:6
示例 4:
输入:numBottles = 2, numExchange = 3
输出:2
提示:
1 <= numBottles <= 100
2 <= numExchange <= 100
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/water-bottles
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 |
|
376. 摆动序列[中等]
如果连续数字之间的差严格地在正数和负数之间交替,则数字序列称为摆动序列。第一个差(如果存在的话)可能是正数或负数。少于两个元素的序列也是摆动序列。
例如, [1,7,4,9,2,5] 是一个摆动序列,因为差值 (6,-3,5,-7,3) 是正负交替出现的。相反, [1,4,7,2,5] 和 [1,7,4,5,5] 不是摆动序列,第一个序列是因为它的前两个差值都是正数,第二个序列是因为它的最后一个差值为零。
给定一个整数序列,返回作为摆动序列的最长子序列的长度。 通过从原始序列中删除一些(也可以不删除)元素来获得子序列,剩下的元素保持其原始顺序。
示例 1:
输入: [1,7,4,9,2,5]
输出: 6
解释: 整个序列均为摆动序列。
示例 2:
输入: [1,17,5,10,13,15,10,5,16,8]
输出: 7
解释: 这个序列包含几个长度为 7 摆动序列,其中一个可为[1,17,10,13,10,16,8]。
示例 3:
输入: [1,2,3,4,5,6,7,8,9]
输出: 2
进阶:
你能否用 O(n) 时间复杂度完成此题
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/wiggle-subsequence
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 |
|
1590. 使数组和能被 P 整除[中等]
给你一个正整数数组 nums,请你移除 最短 子数组(可以为 空),使得剩余元素的 和 能被 p 整除。 不允许 将整个数组都移除。
请你返回你需要移除的最短子数组的长度,如果无法满足题目要求,返回 -1 。
子数组 定义为原数组中连续的一组元素。
示例 1:
输入:nums = [3,1,4,2], p = 6
输出:1
解释:nums 中元素和为 10,不能被 p 整除。我们可以移除子数组 [4] ,剩余元素的和为 6 。
示例 2:
输入:nums = [6,3,5,2], p = 9
输出:2
解释:我们无法移除任何一个元素使得和被 9 整除,最优方案是移除子数组 [5,2] ,剩余元素为 [6,3],和为 9 。
示例 3:
输入:nums = [1,2,3], p = 3
输出:0
解释:和恰好为 6 ,已经能被 3 整除了。所以我们不需要移除任何元素。
示例 4:
输入:nums = [1,2,3], p = 7
输出:-1
解释:没有任何方案使得移除子数组后剩余元素的和被 7 整除。
示例 5:
输入:nums = [1000000000,1000000000,1000000000], p = 3
输出:0
提示:
1 <= nums.length <= 105
1 <= nums[i] <= 109
1 <= p <= 109
通过次数1,854提交次数7,780
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/make-sum-divisible-by-p
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func min(x,y int) int { |
287. 寻找重复数[中等]
给定一个包含 n + 1 个整数的数组 nums,其数字都在 1 到 n 之间(包括 1 和 n),可知至少存在一个重复的整数。假设只有一个重复的整数,找出这个重复的数。
示例 1:
输入: [1,3,4,2,2]
输出: 2
示例 2:
输入: [3,1,3,4,2]
输出: 3
说明:
不能更改原数组(假设数组是只读的)。
只能使用额外的 O(1) 的空间。
时间复杂度小于 O(n2) 。
数组中只有一个重复的数字,但它可能不止重复出现一次。
通过次数110,297提交次数166,875
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/find-the-duplicate-number
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func findDuplicate(nums []int) int { |
744. 寻找比目标字母大的最小字母[简单]
给你一个排序后的字符列表 letters ,列表中只包含小写英文字母。另给出一个目标字母 target,请你寻找在这一有序列表里比目标字母大的最小字母。
在比较时,字母是依序循环出现的。举个例子:
如果目标字母 target = ‘z’ 并且字符列表为 letters = [‘a’, ‘b’],则答案返回 ‘a’
示例:
输入:
letters = [“c”, “f”, “j”]
target = “a”
输出: “c”
输入:
letters = [“c”, “f”, “j”]
target = “c”
输出: “f”
输入:
letters = [“c”, “f”, “j”]
target = “d”
输出: “f”
输入:
letters = [“c”, “f”, “j”]
target = “g”
输出: “j”
输入:
letters = [“c”, “f”, “j”]
target = “j”
输出: “c”
输入:
letters = [“c”, “f”, “j”]
target = “k”
输出: “c”
提示:
letters长度范围在[2, 10000]区间内。
letters 仅由小写字母组成,最少包含两个不同的字母。
目标字母target 是一个小写字母。
通过次数27,173提交次数59,671
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/find-smallest-letter-greater-than-target
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func nextGreatestLetter(letters []byte, target byte) byte { |
278. 第一个错误的版本[简单]
你是产品经理,目前正在带领一个团队开发新的产品。不幸的是,你的产品的最新版本没有通过质量检测。由于每个版本都是基于之前的版本开发的,所以错误的版本之后的所有版本都是错的。
假设你有 n 个版本 [1, 2, …, n],你想找出导致之后所有版本出错的第一个错误的版本。
你可以通过调用 bool isBadVersion(version) 接口来判断版本号 version 是否在单元测试中出错。实现一个函数来查找第一个错误的版本。你应该尽量减少对调用 API 的次数。
示例:
给定 n = 5,并且 version = 4 是第一个错误的版本。
调用 isBadVersion(3) -> false
调用 isBadVersion(5) -> true
调用 isBadVersion(4) -> true
所以,4 是第一个错误的版本。
通过次数73,107提交次数176,199
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/first-bad-version
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func firstBadVersion(n int) int { |
738. 单调递增的数字[中等]
给定一个非负整数 N,找出小于或等于 N 的最大的整数,同时这个整数需要满足其各个位数上的数字是单调递增。
(当且仅当每个相邻位数上的数字 x 和 y 满足 x <= y 时,我们称这个整数是单调递增的。)
示例 1:
输入: N = 10
输出: 9
示例 2:
输入: N = 1234
输出: 1234
示例 3:
输入: N = 332
输出: 299
说明: N 是在 [0, 10^9] 范围内的一个整数。
通过次数24,995提交次数50,506
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/monotone-increasing-digits
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 |
|
106. 从中序与后序遍历序列构造二叉树[中等]
根据一棵树的中序遍历与后序遍历构造二叉树。
注意:
你可以假设树中没有重复的元素。
例如,给出
中序遍历 inorder = [9,3,15,20,7]
后序遍历 postorder = [9,15,7,20,3]
返回如下的二叉树:
3 /
9 20
/
15 7
通过次数80,870提交次数114,177
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/construct-binary-tree-from-inorder-and-postorder-traversal
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func buildTree(inorder []int, postorder []int) *TreeNode { |
560. 和为K的子数组[中等]
给定一个整数数组和一个整数 k,你需要找到该数组中和为 k 的连续的子数组的个数。
示例 1 :
输入:nums = [1,1,1], k = 2
输出: 2 , [1,1] 与 [1,1] 为两种不同的情况。
说明 :
数组的长度为 [1, 20,000]。
数组中元素的范围是 [-1000, 1000] ,且整数 k 的范围是 [-1e7, 1e7]。
通过次数81,696提交次数181,801
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/subarray-sum-equals-k
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 |
|
451. 根据字符出现频率排序[中等]
给定一个字符串,请将字符串里的字符按照出现的频率降序排列。
示例 1:
输入:
“tree”
输出:
“eert”
解释:
‘e’出现两次,’r’和’t’都只出现一次。
因此’e’必须出现在’r’和’t’之前。此外,”eetr”也是一个有效的答案。
示例 2:
输入:
“cccaaa”
输出:
“cccaaa”
解释:
‘c’和’a’都出现三次。此外,”aaaccc”也是有效的答案。
注意”cacaca”是不正确的,因为相同的字母必须放在一起。
示例 3:
输入:
“Aabb”
输出:
“bbAa”
解释:
此外,”bbaA”也是一个有效的答案,但”Aabb”是不正确的。
注意’A’和’a’被认为是两种不同的字符。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/sort-characters-by-frequency
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func frequencySort(s string) string { |
80. 删除排序数组中的重复项 II[中等]
给定一个增序排列数组 nums ,你需要在 原地 删除重复出现的元素,使得每个元素最多出现两次,返回移除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以“引用”方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝
int len = removeDuplicates(nums);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中该长度范围内的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
示例 1:
输入:nums = [1,1,1,2,2,3]
输出:5, nums = [1,1,2,2,3]
解释:函数应返回新长度 length = 5, 并且原数组的前五个元素被修改为 1, 1, 2, 2, 3 。 你不需要考虑数组中超出新长度后面的元素。
示例 2:
输入:nums = [0,0,1,1,1,1,2,3,3]
输出:7, nums = [0,0,1,1,2,3,3]
解释:函数应返回新长度 length = 7, 并且原数组的前五个元素被修改为 0, 0, 1, 1, 2, 3, 3 。 你不需要考虑数组中超出新长度后面的元素。
提示:
0 <= nums.length <= 3 * 104
-104 <= nums[i] <= 104
nums 按递增顺序排列
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/remove-duplicates-from-sorted-array-ii
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func removeDuplicates(nums []int) int { |
102. 二叉树的层序遍历[中等]
给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)。
示例:
二叉树:[3,9,20,null,null,15,7],
3 /
9 20
/
15 7
返回其层次遍历结果:
[
[3],
[9,20],
[15,7]
]
通过次数228,667提交次数358,232
在真实的面试中遇到过这道题?
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/binary-tree-level-order-traversal
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func levelOrder(root *TreeNode) [][]int { |
103. 二叉树的锯齿形层次遍历[中等]
给定一个二叉树,返回其节点值的锯齿形层次遍历。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
例如:
给定二叉树 [3,9,20,null,null,15,7],
3 /
9 20
/
15 7
返回锯齿形层次遍历如下:
[
[3],
[20,9],
[15,7]
]
通过次数83,481提交次数151,198
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/binary-tree-zigzag-level-order-traversal
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func getLevelOrder(root *TreeNode) [][]int { |
714. 买卖股票的最佳时机含手续费[简单]
给定一个整数数组 prices,其中第 i 个元素代表了第 i 天的股票价格 ;非负整数 fee 代表了交易股票的手续费用。
你可以无限次地完成交易,但是你每笔交易都需要付手续费。如果你已经购买了一个股票,在卖出它之前你就不能再继续购买股票了。
返回获得利润的最大值。
注意:这里的一笔交易指买入持有并卖出股票的整个过程,每笔交易你只需要为支付一次手续费。
示例 1:
输入: prices = [1, 3, 2, 8, 4, 9], fee = 2
输出: 8
解释: 能够达到的最大利润:
在此处买入 prices[0] = 1
在此处卖出 prices[3] = 8
在此处买入 prices[4] = 4
在此处卖出 prices[5] = 9
总利润: ((8 - 1) - 2) + ((9 - 4) - 2) = 8.
注意:
0 < prices.length <= 50000.
0 < prices[i] < 50000.
0 <= fee < 50000.
通过次数56,589提交次数81,204
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-with-transaction-fee
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 |
|
152. 乘积最大子数组[中等]
给你一个整数数组 nums ,请你找出数组中乘积最大的连续子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。
示例 1:
输入: [2,3,-2,4]
输出: 6
解释: 子数组 [2,3] 有最大乘积 6。
示例 2:
输入: [-2,0,-1]
输出: 0
解释: 结果不能为 2, 因为 [-2,-1] 不是子数组。
通过次数108,015提交次数265,260
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/maximum-product-subarray
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func maxProduct(nums []int) int { |
898. 子数组按位或操作[中等]
我们有一个非负整数数组 A。
对于每个(连续的)子数组 B = [A[i], A[i+1], …, A[j]] ( i <= j),我们对 B 中的每个元素进行按位或操作,获得结果 A[i] | A[i+1] | … | A[j]。
返回可能结果的数量。 (多次出现的结果在最终答案中仅计算一次。)
示例 1:
输入:[0]
输出:1
解释:
只有一个可能的结果 0 。
示例 2:
输入:[1,1,2]
输出:3
解释:
可能的子数组为 [1],[1],[2],[1, 1],[1, 2],[1, 1, 2]。
产生的结果为 1,1,2,1,3,3 。
有三个唯一值,所以答案是 3 。
示例 3:
输入:[1,2,4]
输出:6
解释:
可能的结果是 1,2,3,4,6,以及 7 。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/bitwise-ors-of-subarrays
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func subarrayBitwiseORs(arr []int) int { |
48. 旋转图像[中等]
给定一个 n × n 的二维矩阵表示一个图像。
将图像顺时针旋转 90 度。
说明:
你必须在原地旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要使用另一个矩阵来旋转图像。
示例 1:
给定 matrix =
[
[1,2,3],
[4,5,6],
[7,8,9]
],
原地旋转输入矩阵,使其变为:
[
[7,4,1],
[8,5,2],
[9,6,3]
]
示例 2:
给定 matrix =
[
[ 5, 1, 9,11],
[ 2, 4, 8,10],
[13, 3, 6, 7],
[15,14,12,16]
],
原地旋转输入矩阵,使其变为:
[
[15,13, 2, 5],
[14, 3, 4, 1],
[12, 6, 8, 9],
[16, 7,10,11]
]
通过次数126,258提交次数176,813
在真实的面试中遇到过这道题?
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/rotate-image
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func rotate(matrix [][]int) { |
316. 去除重复字母[中等]
给你一个字符串 s ,请你去除字符串中重复的字母,使得每个字母只出现一次。需保证 返回结果的字典序最小(要求不能打乱其他字符的相对位置)。
注意:该题与 1081 https://leetcode-cn.com/problems/smallest-subsequence-of-distinct-characters 相同
示例 1:
输入:s = “bcabc”
输出:”abc”
示例 2:
输入:s = “cbacdcbc”
输出:”acdb”
提示:
1 <= s.length <= 104
s 由小写英文字母组成
通过次数36,504提交次数79,575
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/remove-duplicate-letters
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func removeDuplicateLetters(s string) string { |
剑指 Offer 58 - II. 左旋转字符串[简单]
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串”abcdefg”和数字2,该函数将返回左旋转两位得到的结果”cdefgab”。
示例 1:
输入: s = “abcdefg”, k = 2
输出: “cdefgab”
示例 2:
输入: s = “lrloseumgh”, k = 6
输出: “umghlrlose”
限制:
1 <= k < s.length <= 10000
通过次数93,490提交次数109,533
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/zuo-xuan-zhuan-zi-fu-chuan-lcof
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func reverseLeftWords(s string, n int) string { |
523. 连续的子数组和[中等]
给定一个包含 非负数 的数组和一个目标 整数 k,编写一个函数来判断该数组是否含有连续的子数组,其大小至少为 2,且总和为 k 的倍数,即总和为 n*k,其中 n 也是一个整数。
示例 1:
输入:[23,2,4,6,7], k = 6
输出:True
解释:[2,4] 是一个大小为 2 的子数组,并且和为 6。
示例 2:
输入:[23,2,6,4,7], k = 6
输出:True
解释:[23,2,6,4,7]是大小为 5 的子数组,并且和为 42。
说明:
数组的长度不会超过 10,000 。
你可以认为所有数字总和在 32 位有符号整数范围内。
通过次数24,562提交次数109,066
在真实的面试中遇到过这道题?
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/continuous-subarray-sum
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func checkSubarraySum(nums []int, k int) bool { |
135. 分发糖果[困难]
老师想给孩子们分发糖果,有 N 个孩子站成了一条直线,老师会根据每个孩子的表现,预先给他们评分。
你需要按照以下要求,帮助老师给这些孩子分发糖果:
每个孩子至少分配到 1 个糖果。
相邻的孩子中,评分高的孩子必须获得更多的糖果。
那么这样下来,老师至少需要准备多少颗糖果呢?
示例 1:
输入: [1,0,2]
输出: 5
解释: 你可以分别给这三个孩子分发 2、1、2 颗糖果。
示例 2:
输入: [1,2,2]
输出: 4
解释: 你可以分别给这三个孩子分发 1、2、1 颗糖果。
第三个孩子只得到 1 颗糖果,这已满足上述两个条件。
通过次数52,554提交次数110,962
在真实的面试中遇到过这道题?
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/candy
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 |
|
1046. 最后一块石头的重量[简单]
有一堆石头,每块石头的重量都是正整数。
每一回合,从中选出两块 最重的 石头,然后将它们一起粉碎。假设石头的重量分别为 x 和 y,且 x <= y。那么粉碎的可能结果如下:
如果 x == y,那么两块石头都会被完全粉碎;
如果 x != y,那么重量为 x 的石头将会完全粉碎,而重量为 y 的石头新重量为 y-x。
最后,最多只会剩下一块石头。返回此石头的重量。如果没有石头剩下,就返回 0。
示例:
输入:[2,7,4,1,8,1]
输出:1
解释:
先选出 7 和 8,得到 1,所以数组转换为 [2,4,1,1,1],
再选出 2 和 4,得到 2,所以数组转换为 [2,1,1,1],
接着是 2 和 1,得到 1,所以数组转换为 [1,1,1],
最后选出 1 和 1,得到 0,最终数组转换为 [1],这就是最后剩下那块石头的重量。
提示:
1 <= stones.length <= 30
1 <= stones[i] <= 1000
通过次数46,177提交次数70,535
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/last-stone-weight
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func lastStoneWeight(stones []int) int { |
977. 有序数组的平方[简单]
给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。
示例 1:
输入:nums = [-4,-1,0,3,10]
输出:[0,1,9,16,100]
解释:平方后,数组变为 [16,1,0,9,100]
排序后,数组变为 [0,1,9,16,100]
示例 2:
输入:nums = [-7,-3,2,3,11]
输出:[4,9,9,49,121]
提示:
1 <= nums.length <= 104
-104 <= nums[i] <= 104
nums 已按 非递减顺序 排序
进阶:
请你设计时间复杂度为 O(n) 的算法解决本问题
通过次数91,837提交次数125,028
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/squares-of-a-sorted-array
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func sortedSquares(nums []int) []int { |
830. 较大分组的位置[简单]
在一个由小写字母构成的字符串 s 中,包含由一些连续的相同字符所构成的分组。
例如,在字符串 s = “abbxxxxzyy” 中,就含有 “a”, “bb”, “xxxx”, “z” 和 “yy” 这样的一些分组。
分组可以用区间 [start, end] 表示,其中 start 和 end 分别表示该分组的起始和终止位置的下标。上例中的 “xxxx” 分组用区间表示为 [3,6] 。
我们称所有包含大于或等于三个连续字符的分组为 较大分组 。
找到每一个 较大分组 的区间,按起始位置下标递增顺序排序后,返回结果。
示例 1:
输入:s = “abbxxxxzzy”
输出:[[3,6]]
解释:”xxxx” 是一个起始于 3 且终止于 6 的较大分组。
示例 2:
输入:s = “abc”
输出:[]
解释:”a”,”b” 和 “c” 均不是符合要求的较大分组。
示例 3:
输入:s = “abcdddeeeeaabbbcd”
输出:[[3,5],[6,9],[12,14]]
解释:较大分组为 “ddd”, “eeee” 和 “bbb”
示例 4:
输入:s = “aba”
输出:[]
提示:
1 <= s.length <= 1000
s 仅含小写英文字母
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/positions-of-large-groups
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func largeGroupPositions(s string) [][]int { |
1018. 可被 5 整除的二进制前缀[简单]
给定由若干 0 和 1 组成的数组 A。我们定义 N_i:从 A[0] 到 A[i] 的第 i 个子数组被解释为一个二进制数(从最高有效位到最低有效位)。
返回布尔值列表 answer,只有当 N_i 可以被 5 整除时,答案 answer[i] 为 true,否则为 false。
示例 1:
输入:[0,1,1]
输出:[true,false,false]
解释:
输入数字为 0, 01, 011;也就是十进制中的 0, 1, 3 。只有第一个数可以被 5 整除,因此 answer[0] 为真。
示例 2:
输入:[1,1,1]
输出:[false,false,false]
示例 3:
输入:[0,1,1,1,1,1]
输出:[true,false,false,false,true,false]
示例 4:
输入:[1,1,1,0,1]
输出:[false,false,false,false,false]
提示:
1 <= A.length <= 30000
A[i] 为 0 或 1
通过次数33,869提交次数65,889
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/binary-prefix-divisible-by-5
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func prefixesDivBy5(A []int) []bool { |
1004. 最大连续1的个数 III[中等]
给定一个由若干 0 和 1 组成的数组 A,我们最多可以将 K 个值从 0 变成 1 。
返回仅包含 1 的最长(连续)子数组的长度。
示例 1:
输入:A = [1,1,1,0,0,0,1,1,1,1,0], K = 2
输出:6
解释:
[1,1,1,0,0,1,1,1,1,1,1]
粗体数字从 0 翻转到 1,最长的子数组长度为 6。
示例 2:
输入:A = [0,0,1,1,0,0,1,1,1,0,1,1,0,0,0,1,1,1,1], K = 3
输出:10
解释:
[0,0,1,1,1,1,1,1,1,1,1,1,0,0,0,1,1,1,1]
粗体数字从 0 翻转到 1,最长的子数组长度为 10。
提示:
1 <= A.length <= 20000
0 <= K <= A.length
A[i] 为 0 或 1
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/max-consecutive-ones-iii
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法
1 | func longestOnes(A []int, K int) int { |
766. 托普利茨矩阵[简单]
给你一个 m x n 的矩阵 matrix 。如果这个矩阵是托普利茨矩阵,返回 true ;否则,返回 false 。
如果矩阵上每一条由左上到右下的对角线上的元素都相同,那么这个矩阵是 托普利茨矩阵 。
示例 1:
输入:matrix = [[1,2,3,4],[5,1,2,3],[9,5,1,2]]
输出:true
解释:
在上述矩阵中, 其对角线为:
“[9]”, “[5, 5]”, “[1, 1, 1]”, “[2, 2, 2]”, “[3, 3]”, “[4]”。
各条对角线上的所有元素均相同, 因此答案是 True 。
示例 2:
输入:matrix = [[1,2],[2,2]]
输出:false
解释:
对角线 “[1, 2]” 上的元素不同。
提示:
m == matrix.length
n == matrix[i].length
1 <= m, n <= 20
0 <= matrix[i][j] <= 99
进阶:
如果矩阵存储在磁盘上,并且内存有限,以至于一次最多只能将矩阵的一行加载到内存中,该怎么办?
如果矩阵太大,以至于一次只能将不完整的一行加载到内存中,该怎么办?
通过次数43,372提交次数61,387
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/toeplitz-matrix
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
solution
1 | func isToeplitzMatrix(matrix [][]int) bool { |
1052. 爱生气的书店老板[中等]
今天,书店老板有一家店打算试营业 customers.length 分钟。每分钟都有一些顾客(customers[i])会进入书店,所有这些顾客都会在那一分钟结束后离开。
在某些时候,书店老板会生气。 如果书店老板在第 i 分钟生气,那么 grumpy[i] = 1,否则 grumpy[i] = 0。 当书店老板生气时,那一分钟的顾客就会不满意,不生气则他们是满意的。
书店老板知道一个秘密技巧,能抑制自己的情绪,可以让自己连续 X 分钟不生气,但却只能使用一次。
请你返回这一天营业下来,最多有多少客户能够感到满意的数量。
示例:
输入:customers = [1,0,1,2,1,1,7,5], grumpy = [0,1,0,1,0,1,0,1], X = 3
输出:16
解释:
书店老板在最后 3 分钟保持冷静。
感到满意的最大客户数量 = 1 + 1 + 1 + 1 + 7 + 5 = 16.
提示:
1 <= X <= customers.length == grumpy.length <= 20000
0 <= customers[i] <= 1000
0 <= grumpy[i] <= 1
通过次数32,682提交次数56,341
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/grumpy-bookstore-owner
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
solution
1 | func maxSatisfied(customers []int, grumpy []int, X int) int { |
395. 至少有K个重复字符的最长子串[中等]
找到给定字符串(由小写字符组成)中的最长子串 T , 要求 T 中的每一字符出现次数都不少于 k 。输出 T 的长度。
示例 1:
输入:
s = “aaabb”, k = 3
输出:
3
最长子串为 “aaa” ,其中 ‘a’ 重复了 3 次。
示例 2:
输入:
s = “ababbc”, k = 2
输出:
5
最长子串为 “ababb” ,其中 ‘a’ 重复了 2 次, ‘b’ 重复了 3 次。
通过次数18,939提交次数41,163
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/longest-substring-with-at-least-k-repeating-characters
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
solution
1 | func longestSubstring(s string, k int) int { |
翻转图像
给定一个二进制矩阵 A,我们想先水平翻转图像,然后反转图像并返回结果。
水平翻转图片就是将图片的每一行都进行翻转,即逆序。例如,水平翻转 [1, 1, 0] 的结果是 [0, 1, 1]。
反转图片的意思是图片中的 0 全部被 1 替换, 1 全部被 0 替换。例如,反转 [0, 1, 1] 的结果是 [1, 0, 0]。
示例 1:
输入:[[1,1,0],[1,0,1],[0,0,0]]
输出:[[1,0,0],[0,1,0],[1,1,1]]
解释:首先翻转每一行: [[0,1,1],[1,0,1],[0,0,0]];
然后反转图片: [[1,0,0],[0,1,0],[1,1,1]]
示例 2:
输入:[[1,1,0,0],[1,0,0,1],[0,1,1,1],[1,0,1,0]]
输出:[[1,1,0,0],[0,1,1,0],[0,0,0,1],[1,0,1,0]]
解释:首先翻转每一行: [[0,0,1,1],[1,0,0,1],[1,1,1,0],[0,1,0,1]];
然后反转图片: [[1,1,0,0],[0,1,1,0],[0,0,0,1],[1,0,1,0]]
提示:
1 <= A.length = A[0].length <= 20
0 <= A[i][j] <= 1
通过次数71,692提交次数90,217
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/flipping-an-image
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
翻转图像
给定一个二进制矩阵 A,我们想先水平翻转图像,然后反转图像并返回结果。
水平翻转图片就是将图片的每一行都进行翻转,即逆序。例如,水平翻转 [1, 1, 0] 的结果是 [0, 1, 1]。
反转图片的意思是图片中的 0 全部被 1 替换, 1 全部被 0 替换。例如,反转 [0, 1, 1] 的结果是 [1, 0, 0]。
示例 1:
输入:[[1,1,0],[1,0,1],[0,0,0]]
输出:[[1,0,0],[0,1,0],[1,1,1]]
解释:首先翻转每一行: [[0,1,1],[1,0,1],[0,0,0]];
然后反转图片: [[1,0,0],[0,1,0],[1,1,1]]
示例 2:
输入:[[1,1,0,0],[1,0,0,1],[0,1,1,1],[1,0,1,0]]
输出:[[1,1,0,0],[0,1,1,0],[0,0,0,1],[1,0,1,0]]
解释:首先翻转每一行: [[0,0,1,1],[1,0,0,1],[1,1,1,0],[0,1,0,1]];
然后反转图片: [[1,1,0,0],[0,1,1,0],[0,0,0,1],[1,0,1,0]]
提示:
1 <= A.length = A[0].length <= 20
0 <= A[i][j] <= 1
通过次数71,692提交次数90,217
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/flipping-an-image
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
solution
1 | func flipAndInvertImage(A [][]int) [][]int { |
1178. 猜字谜
外国友人仿照中国字谜设计了一个英文版猜字谜小游戏,请你来猜猜看吧。
字谜的迷面 puzzle 按字符串形式给出,如果一个单词 word 符合下面两个条件,那么它就可以算作谜底:
单词 word 中包含谜面 puzzle 的第一个字母。
单词 word 中的每一个字母都可以在谜面 puzzle 中找到。
例如,如果字谜的谜面是 “abcdefg”,那么可以作为谜底的单词有 “faced”, “cabbage”, 和 “baggage”;而 “beefed”(不含字母 “a”)以及 “based”(其中的 “s” 没有出现在谜面中)都不能作为谜底。
返回一个答案数组 answer,数组中的每个元素 answer[i] 是在给出的单词列表 words 中可以作为字谜迷面 puzzles[i] 所对应的谜底的单词数目。
示例:
输入:
words = [“aaaa”,”asas”,”able”,”ability”,”actt”,”actor”,”access”],
puzzles = [“aboveyz”,”abrodyz”,”abslute”,”absoryz”,”actresz”,”gaswxyz”]
输出:[1,1,3,2,4,0]
解释:
1 个单词可以作为 “aboveyz” 的谜底 : “aaaa”
1 个单词可以作为 “abrodyz” 的谜底 : “aaaa”
3 个单词可以作为 “abslute” 的谜底 : “aaaa”, “asas”, “able”
2 个单词可以作为 “absoryz” 的谜底 : “aaaa”, “asas”
4 个单词可以作为 “actresz” 的谜底 : “aaaa”, “asas”, “actt”, “access”
没有单词可以作为 “gaswxyz” 的谜底,因为列表中的单词都不含字母 ‘g’。
提示:
1 <= words.length <= 10^5
4 <= words[i].length <= 50
1 <= puzzles.length <= 10^4
puzzles[i].length == 7
words[i][j], puzzles[i][j] 都是小写英文字母。
每个 puzzles[i] 所包含的字符都不重复。
通过次数11,961提交次数28,439
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/number-of-valid-words-for-each-puzzle
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
solution
1 | func findNumOfValidWords(words []string, puzzles []string) []int { |
896. 单调数列[easy]
如果数组是单调递增或单调递减的,那么它是单调的。
如果对于所有 i <= j,A[i] <= A[j],那么数组 A 是单调递增的。 如果对于所有 i <= j,A[i]> = A[j],那么数组 A 是单调递减的。
当给定的数组 A 是单调数组时返回 true,否则返回 false。
示例 1:
输入:[1,2,2,3]
输出:true
示例 2:
输入:[6,5,4,4]
输出:true
示例 3:
输入:[1,3,2]
输出:false
示例 4:
输入:[1,2,4,5]
输出:true
示例 5:
输入:[1,1,1]
输出:true
提示:
1 <= A.length <= 50000
-100000 <= A[i] <= 100000
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/monotonic-array
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
solution
1 | func isMonotonic(A []int) bool { |
面试题 17.18. 最短超串[中等]
假设你有两个数组,一个长一个短,短的元素均不相同。找到长数组中包含短数组所有的元素的最短子数组,其出现顺序无关紧要。
返回最短子数组的左端点和右端点,如有多个满足条件的子数组,返回左端点最小的一个。若不存在,返回空数组。
示例 1:
输入:
big = [7,5,9,0,2,1,3,5,7,9,1,1,5,8,8,9,7]
small = [1,5,9]
输出: [7,10]
示例 2:
输入:
big = [1,2,3]
small = [4]
输出: []
提示:
big.length <= 100000
1 <= small.length <= 100000
通过次数4,545提交次数10,344
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/shortest-supersequence-lcci
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
solution
滑动窗口只要想清楚怎么进,怎么出就行了。
1 | func checksub(bMap map[int]int, sMap map[int]int) bool { |
338. 比特位计数[m]
给定一个非负整数 num。对于 0 ≤ i ≤ num 范围中的每个数字 i ,计算其二进制数中的 1 的数目并将它们作为数组返回。
示例 1:
输入: 2
输出: [0,1,1]
示例 2:
输入: 5
输出: [0,1,1,2,1,2]
进阶:
给出时间复杂度为O(n*sizeof(integer))的解答非常容易。但你可以在线性时间O(n)内用一趟扫描做到吗?
要求算法的空间复杂度为O(n)。
你能进一步完善解法吗?要求在C++或任何其他语言中不使用任何内置函数(如 C++ 中的 __builtin_popcount)来执行此操作。
通过次数107,862提交次数136,687
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/counting-bits
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
solution
1 | func countBits(num int) []int { |
1006. 笨阶乘[m]
通常,正整数 n 的阶乘是所有小于或等于 n 的正整数的乘积。例如,factorial(10) = 10 * 9 * 8 * 7 * 6 * 5 * 4 * 3 * 2 * 1。
相反,我们设计了一个笨阶乘 clumsy:在整数的递减序列中,我们以一个固定顺序的操作符序列来依次替换原有的乘法操作符:乘法(*),除法(/),加法(+)和减法(-)。
例如,clumsy(10) = 10 * 9 / 8 + 7 - 6 * 5 / 4 + 3 - 2 * 1。然而,这些运算仍然使用通常的算术运算顺序:我们在任何加、减步骤之前执行所有的乘法和除法步骤,并且按从左到右处理乘法和除法步骤。
另外,我们使用的除法是地板除法(floor division),所以 10 * 9 / 8 等于 11。这保证结果是一个整数。
实现上面定义的笨函数:给定一个整数 N,它返回 N 的笨阶乘。
示例 1:
输入:4
输出:7
解释:7 = 4 * 3 / 2 + 1
示例 2:
输入:10
输出:12
解释:12 = 10 * 9 / 8 + 7 - 6 * 5 / 4 + 3 - 2 * 1
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/clumsy-factorial
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
solution
1 | func clumsy(N int) int { |
面试题 17.21. 直方图的水量[h]
给定一个直方图(也称柱状图),假设有人从上面源源不断地倒水,最后直方图能存多少水量?直方图的宽度为 1。
上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的直方图,在这种情况下,可以接 6 个单位的水(蓝色部分表示水)。 感谢 Marcos 贡献此图。
示例:
输入: [0,1,0,2,1,0,1,3,2,1,2,1]
输出: 6
通过次数29,968提交次数47,826
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/volume-of-histogram-lcci
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
solution
1 | func min(x,y int) int { |
丑数[e]
给你一个整数 n ,请你判断 n 是否为 丑数 。如果是,返回 true ;否则,返回 false 。
丑数 就是只包含质因数 2、3 和/或 5 的正整数。
示例 1:
输入:n = 6
输出:true
解释:6 = 2 × 3
示例 2:
输入:n = 8
输出:true
解释:8 = 2 × 2 × 2
示例 3:
输入:n = 14
输出:false
解释:14 不是丑数,因为它包含了另外一个质因数 7 。
示例 4:
输入:n = 1
输出:true
解释:1 通常被视为丑数。
提示:
-231 <= n <= 231 - 1
通过次数81,651提交次数159,582
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/ugly-number
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
solution
只能2/3/5去除尽,理论上n = 2^i + 3^j + 5^k。除尽之后只剩下1,剩下别的数说明是假的。
1 | var factors = []int{2, 3, 5} |
1310. 子数组异或查询[m]
有一个正整数数组 arr,现给你一个对应的查询数组 queries,其中 queries[i] = [Li, Ri]。
对于每个查询 i,请你计算从 Li 到 Ri 的 XOR 值(即 arr[Li] xor arr[Li+1] xor … xor arr[Ri])作为本次查询的结果。
并返回一个包含给定查询 queries 所有结果的数组。
示例 1:
输入:arr = [1,3,4,8], queries = [[0,1],[1,2],[0,3],[3,3]]
输出:[2,7,14,8]
解释:
数组中元素的二进制表示形式是:
1 = 0001
3 = 0011
4 = 0100
8 = 1000
查询的 XOR 值为:
[0,1] = 1 xor 3 = 2
[1,2] = 3 xor 4 = 7
[0,3] = 1 xor 3 xor 4 xor 8 = 14
[3,3] = 8
示例 2:
输入:arr = [4,8,2,10], queries = [[2,3],[1,3],[0,0],[0,3]]
输出:[8,0,4,4]
提示:
1 <= arr.length <= 3 * 10^4
1 <= arr[i] <= 10^9
1 <= queries.length <= 3 * 10^4
queries[i].length == 2
0 <= queries[i][0] <= queries[i][1] < arr.length
通过次数28,447提交次数40,162
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/xor-queries-of-a-subarray
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
solution
A ^ B = C
C ^ A = B
C ^ B = A
1 | func xorQueries(arr []int, queries [][]int) []int { |
在二叉树中,根节点位于深度 0 处,每个深度为 k 的节点的子节点位于深度 k+1 处。
如果二叉树的两个节点深度相同,但 父节点不同 ,则它们是一对堂兄弟节点。
我们给出了具有唯一值的二叉树的根节点 root ,以及树中两个不同节点的值 x 和 y 。
只有与值 x 和 y 对应的节点是堂兄弟节点时,才返回 true 。否则,返回 false。
示例 1:
输入:root = [1,2,3,4], x = 4, y = 3
输出:false
示例 2:
输入:root = [1,2,3,null,4,null,5], x = 5, y = 4
输出:true
示例 3:
输入:root = [1,2,3,null,4], x = 2, y = 3
输出:false
提示:
二叉树的节点数介于 2 到 100 之间。
每个节点的值都是唯一的、范围为 1 到 100 的整数。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/cousins-in-binary-tree
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
solution
1 | // 深度和父亲 |
342. 4的幂[m]
给定一个整数,写一个函数来判断它是否是 4 的幂次方。如果是,返回 true ;否则,返回 false 。
整数 n 是 4 的幂次方需满足:存在整数 x 使得 n == 4x
示例 1:
输入:n = 16
输出:true
示例 2:
输入:n = 5
输出:false
示例 3:
输入:n = 1
输出:true
提示:
-231 <= n <= 231 - 1
进阶:
你能不使用循环或者递归来完成本题吗?
通过次数74,204提交次数144,847
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/power-of-four
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
solution
使用mask
1 | func isPowerOfFour(n int) bool { |
使用模
func isPowerOfFour(n int) bool {
return n > 0 && n &(n - 1) == 0 && n % 3 == 1
}
``