爬取目的
为了下载b站的教学视频url地址,便于使用唧唧来下载视频
爬取的信息
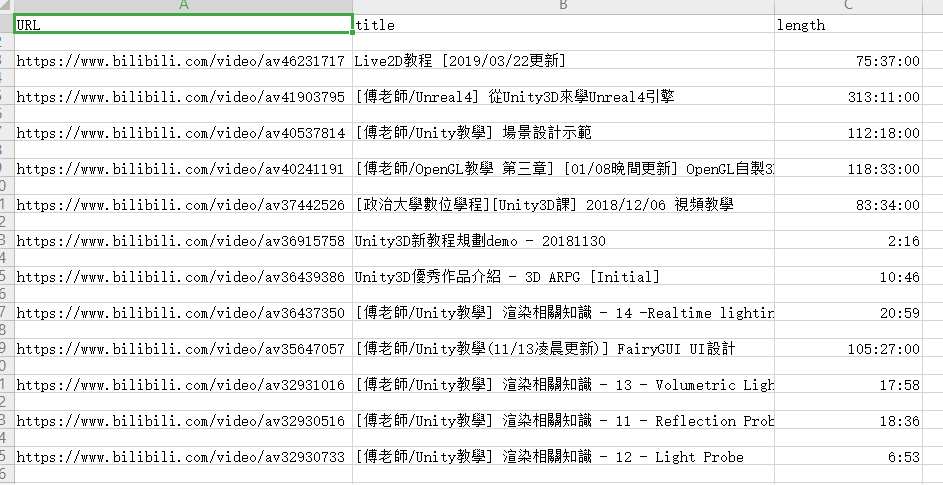
视频的URL,视频的title,视频的时长length
存储的格式

关键步骤
由于使用异步加载的方式加载页面,所以不能用传统的方式来爬取
1、获得所需的数据接口

通过更改page的值便可以获得下一个页面的视频数据
返回的数据是json数据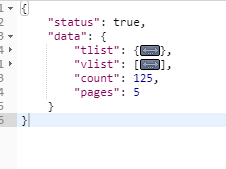
vlist数据和pages数据是自己需要的数据
vlist数据格式
从vlist数据中提取出
aid 视频的av号
title 视频的标题
length 视频的长度
Python代码
1 |
|
爬取结果